哈夫曼树和哈夫曼编码
哈夫曼编码是一种用于数据压缩的编码方式,它使用变长编码来表示数据源中的符号。频率较高的符号用较短的编码,频率较低的符号用较长的编码,从而达到减少总编码长度的目的。
编码过程

例子:
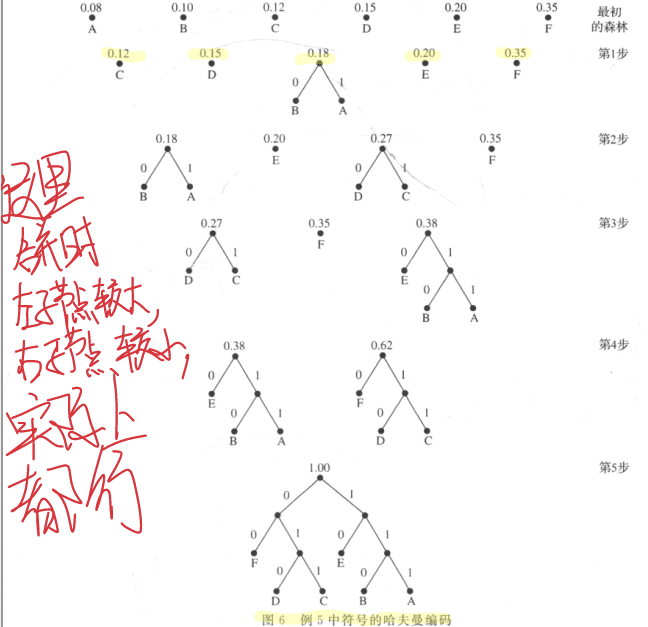
对字母进行哈夫曼编码时的性质:
1.每个字母对应元素叶节点的值是该字母出现的次数
2.出现次数越多的字符编码越短
3.不出现歧义的情况下编出来的码长度最短
4.编码结果不唯一,字母编出来的码可能不一样,但是长度肯定一样
参考b站视频:哈夫曼树和哈夫曼编码, 看完秒懂!
不会出现歧义原因:不存在任意一个元素节点出现在另一个元素节点的路径中
应用: 压缩文件
代码实现
1 |
|
这段代码首先统计了输入字符串中每个字符出现的频率,然后创建了一个最小堆(priority_queue),其中存储的是由字符及其频率组成的节点。通过不断地从堆中取出两个频率最低的节点并合并成一个新的节点,最终构建出哈夫曼树。之后,通过遍历哈夫曼树生成每个字符对应的编码,并将这些编码存储在一个映射表中。最后,根据这个映射表对原始字符串进行编码。
请注意,这个简单的实现并没有包括解码过程、内存释放或者处理可能的异常情况。在实际应用中,你还需要考虑这些问题。此外,由于C++标准库中没有直接支持优先队列元素为自定义类型的比较,我们重载了小于操作符以适应 priority_queue 的需求。
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Lee的学习之旅!
相关推荐

2025-02-07
C++笔记
C++参考文档 课程链接:国外公认讲的最好的【C++教程】技术大佬带你从零基础入门到精通,油管百万级收藏,学C++看这个就够了! 变量 变量类型 占用内存的字节数(byte) int 4 char 1 short 2 long 4 long long 8 float 4 double 8 bool 1 变量前加unsigned即舍弃符号位,能表示的数值的最大值为原来的两倍 字符 ASCII表上对应的值 0 48 a 97 A 65 例子: 1234567char a=65;cout<<a<<endl;//输出为字符A//------------------float b=5.5;//此时b为double类型float...
2025-02-09
C和C++的区别

2025-02-27
第2章 算法效率分析基础
2.2 渐进符号和基本效率类型 类型按照增长次数的升序排列 2.4 递归算法的数学分析反向替代法 分析递归算法时间效率的通用方案 汉诺塔游戏 手写的详细步骤四个盘子时: 代码实现123456789101112131415161718192021222324252627282930#include <stdio.h>int m=0;void Move(int n,char A,char B,char C)//A和B柱并不固定,可以互换,A是盘子所在的塔,B是辅助塔,C是目标塔,函数的目的是把A上的n个盘子通过B全部转移到C{ m++; //设置移动盘子的结束条件(当只有一个盘子时直接从A或B柱移到C柱),如果A当前还有一个盘子那么就把他直接移动到C if(n == 1) { printf("%c -> %c\n",A,C); } //否则开始递归 else ...
2025-02-27
第3章 蛮力法
3.2 顺序查找和蛮力字符串匹配顺序查找: 1234567891011121314151617181920#include<iostream>#include<cstring>using namespace std;int SequentialSearch(string& a,char b){ int i=0; while(i<a.length()&&a[i++]!=b); if(a[i-1]==b)i--; if(i<a.length())return i; else return -1;}int main(){ string a="abbbbc"; cout<<SequentialSearch(a,'d')<<endl; cin.get(); return...

2026-01-23
滑动窗口算法框架
123456789101112131415161718192021222324252627282930313233343536// 滑动窗口算法伪码框架void slidingWindow(string s) { // 用合适的数据结构记录窗口中的数据,根据具体场景变通 // 比如说,我想记录窗口中元素出现的次数,就用 map // 如果我想记录窗口中的元素和,就可以只用一个 int auto window = ... int left = 0, right = 0; while (right < s.size()) { // c 是将移入窗口的字符 char c = s[right]; window.add(c); // 增大窗口 right++; // 进行窗口内数据的一系列更新 ... // *** debug 输出的位置 *** printf("window: [%d,...
2025-03-15
第4章 减治法
4.1 插入排序插排的代码可看数据结构中排序那部分 4.3 生成组合对象的算法Johnson-Trotter算法 1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556575859606162636465666768697071727374757677#include <iostream>#include <vector>// 检查元素是否可移动bool canMove(const std::vector<int>& perm, const std::vector<int>& dir, int index) { int d = dir[index]; if (d == -1 && index > 0 && perm[index] > perm[index - 1]) { ...