灰色关联分析
原理
灰色关联分析(Grey Relational Analysis, GRA)是一种多因素统计分析方法,它主要用于处理小样本、贫信息不确定性问题。灰色系统理论是基于部分已知信息和部分未知信息的系统,由我国学者邓聚龙教授于1982年提出。灰色关联分析可以用于评估不同序列之间的关联程度,广泛应用于工程、经济、环境科学等多个领域。
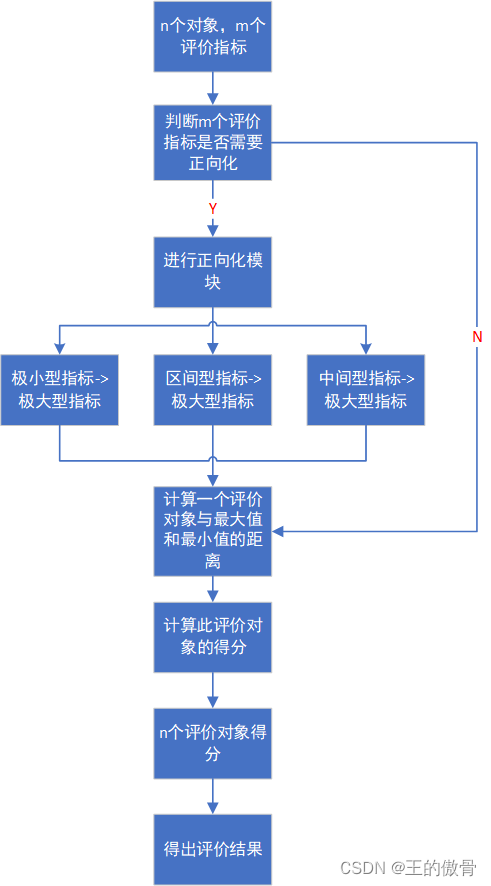
灰色关联分析的基本步骤:
确定比较序列和参考序列:
- 比较序列是指需要与参考序列进行对比的多个序列。
- 参考序列是作为标准或目标的序列,通常选择最优或者最差的序列作为参考。
对原始数据进行无量纲化处理:
- 由于不同指标的数据可能具有不同的量纲(单位),为了消除量纲的影响,需要对原始数据进行无量纲化处理,常用的方法有初值化、均值化等。
计算关联系数:
- 根据公式计算比较序列中的每个点与参考序列对应点之间的关联系数。关联系数反映了两序列在某一点上的关联程度,其值一般介于0和1之间。
计算关联度:
- 关联度是对所有时间点上关联系数的一个综合评价,通过加权平均或者其他方式得到。
根据关联度排序:
- 对比序列按照关联度大小排序,关联度越大说明该序列与参考序列越相似,反之则差异越大。
结果分析:
分析排序结果,得出结论,并据此为决策提供依据。



应用实例:
例如,在评估某个地区经济发展状况时,可以选取GDP、人均收入、工业总产值等若干个经济指标构成比较序列,以全国平均水平或者理想水平作为参考序列,通过灰色关联分析找出哪些因素与经济发展最相关,从而为政策制定提供参考。
灰色关联分析的优点在于它不需要大量的样本数据,也不要求数据服从特定的概率分布,因此对于一些难以获取大量数据的情况非常适用。但是,它的缺点是主观性较强,比如在选择参考序列、权重分配等方面可能会引入人为因素,影响分析结果的客观性。
代码
code1(无需正向化)
1 | %% 灰色关联分析用于系统分析例题的讲解 |
code2(要判断是否需要正向化)
1 | clear;clc |
用于正向化的函数
Inter2Max
1 | function [posit_x] = Inter2Max(x,a,b) |
Mid2Max
1 | function [posit_x] = Mid2Max(x,best) |
Min2Max
1 | function [posit_x] = Min2Max(x) |
Positivization
1 | % function [输出变量] = 函数名称(输入变量) |
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Lee的学习之旅!
相关推荐
2025-01-02
TOPSIS法
原理TOPSIS(Technique for Order Preference by Similarity to Ideal...
2025-01-14
一元线性回归分析模型
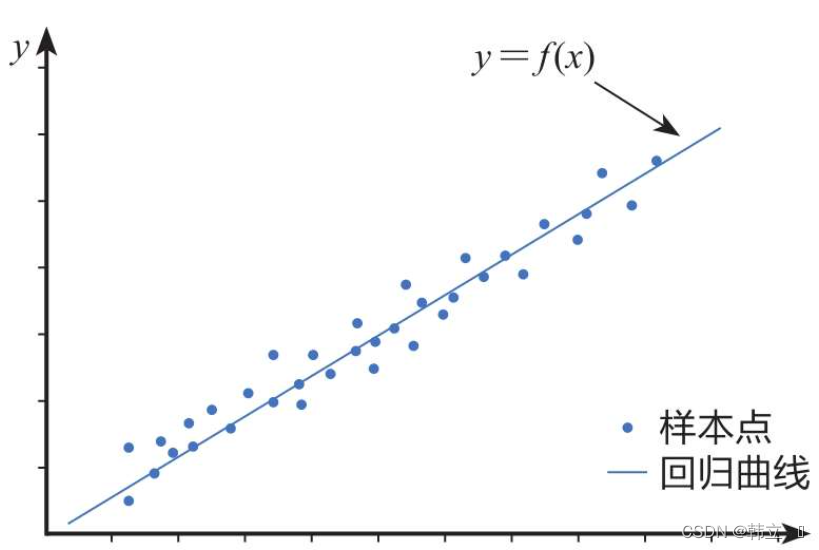
原理一元线性回归分析模型(Simple Linear Regression Model)是一种统计方法,用于研究两个连续变量之间的关系:一个因变量(通常记为 (Y))和一个自变量(通常记为 (X))。这个模型假设这两个变量之间存在线性关系,并试图通过最小化预测值与实际观测值之间的差异来拟合一条直线。 残差图作图命令:rcoplot(r,rint) 建模步骤 数据收集:首先需要收集包含因变量和自变量的数据集。 模型设定:设定一元线性回归模型的形式,即 (Y = \beta_0 + \beta_1 X + \epsilon)。 参数估计:使用最小二乘法(Ordinary Least Squares, OLS)等方法来估计未知参数 (\beta_0) 和 (\beta_1)。OLS的目标是找到使残差平方和最小化的参数值,即 (\sum (Y_i - (\beta_0 + \beta_1 X_i))^2)...
2025-01-14
动态规划模型
原理动态规划(Dynamic...
2025-03-18
函数极值与规划模型
矩阵运算12345678910111213141516171819202122232425import numpy as npa=np.array([[1,2,3],[4,5,6]])b=np.array([[1,2],[3,4],[5,6]])c=np.array([[1,2,3]])d=np.array([[9,8,7],[3,2,1]])#矩阵加法sum=a+d#放缩e=3*a#数乘、矩阵乘e=np.dot(a,b)#元素乘e=a*dprint(e)#转置e=c.Tprint(e)e=np.array([[1,2],[3,4]])#逆矩阵result=np.linalg.inv(e)#行列式result=np.linalg.det(e)#矩阵的秩e=np.linalg.matrix_rank(d)print(e) 求一次方程组的解 1234567891011121314151617import numpy as np#用于第一段代码from sympy import...
2025-01-14
图论模型
Matlab作无向图(1)无权重(每条边的权重默认为1)函数**graph(s,t)**:可在 s 和 t 中的对应节点之间创建边,并生成一个图 s 和 t 都必须具有相同的元素数;这些节点必须都是从1开始的正整数,或都是字符串元胞数组。 注意哦,编号最好是从1开始连续编号,不要自己随便定义编号 123456789101112131415s1 = [1,2,3,4];t1 = [2,3,1,1];G1 = graph(s1, t1);plot(G1)% 下面的命令是在画图后不显示坐标set( gca, 'XTick', [], 'YTick', [] ); % 注意字符串元胞数组是用大括号包起来的哦s2 = {'学校','电影院','网吧','酒店'};t2 = {'电影院','酒店','酒店','KTV'};G2 = graph(s2,...
2025-01-12
主成分分析法
原理主成分分析法(Principal Component...