决策树
决策树
参考教程:(超爽中英!) 2025公认最好的【吴恩达机器学习】教程!附课件代码 Machine Learning Specialization
C2 - Advanced Learning Algorithms-week4
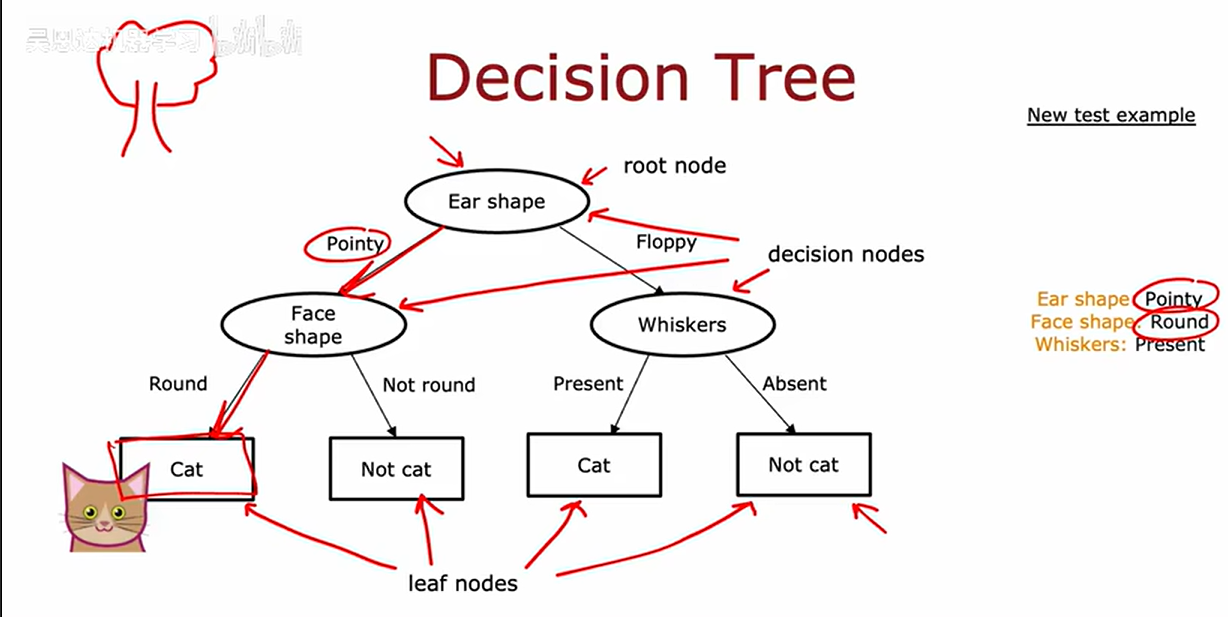
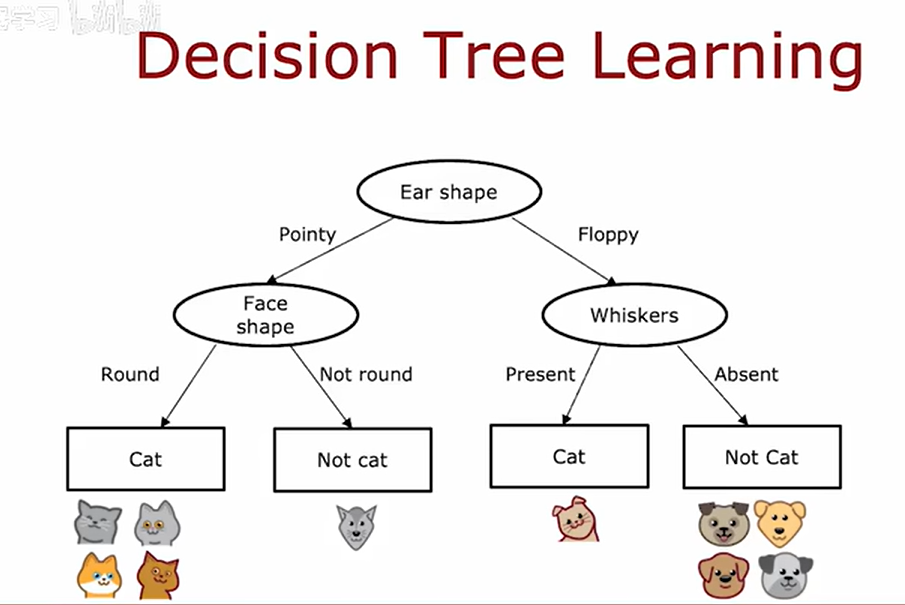
学习过程
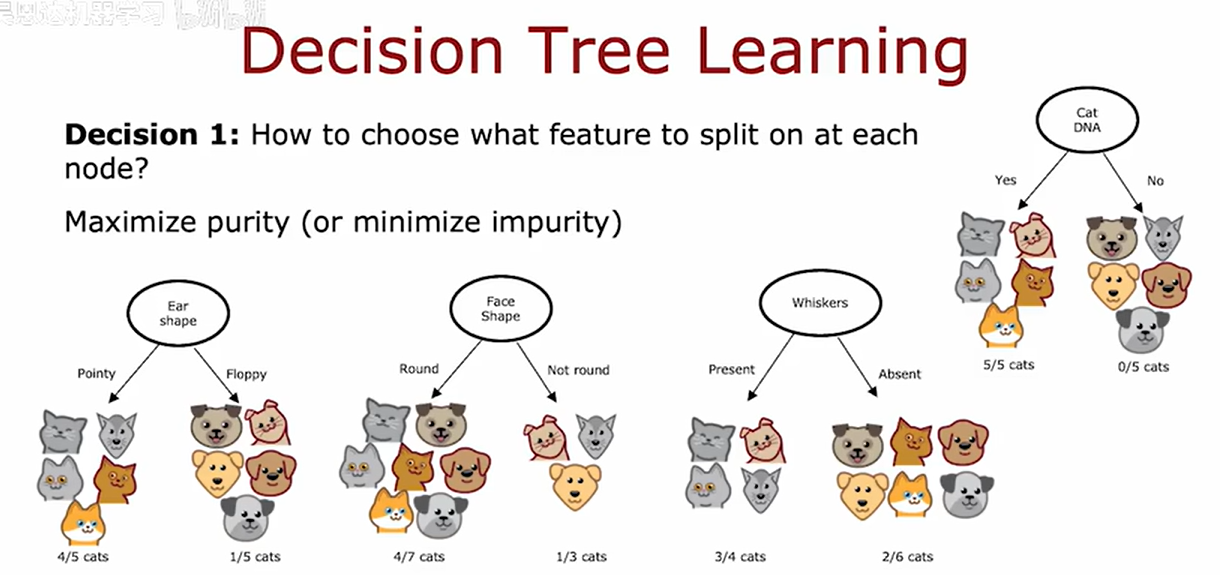

测量纯度

$H(p_1)$表示$p_1$的熵值,表示不纯度,熵值越大表示样本集越不纯(pure)

熵函数:
$p_0=1-p_1$
$H(p_1)=-p_1log_2(p_1)-p_0log_2(p_0)=-p_1log_2(p_1)-(1-p_1)log_2(1-p_1)$
取log的底数为2使得函数的峰值为1,把0log(0)看作0
选择拆分信息增益


熵:$H(p)=-\sum_{i=1}^{n}p_ilog_2p_i$
条件熵:$H(Y|X)=\sum_{i=1}^np_iH(Y|X=x_i)$
信息增益:$g(X,Y)=H(Y)-H(Y|X)$
整合

使用独热编码

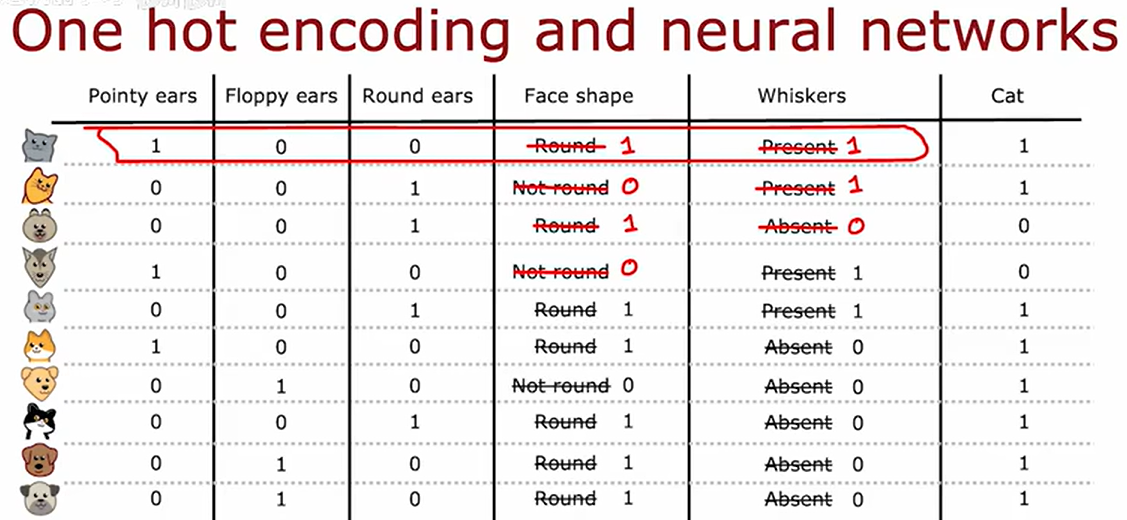
当决策树中的某个特征的离散值数量超过两个时可以使用 one hot encoding
连续的有价值特征
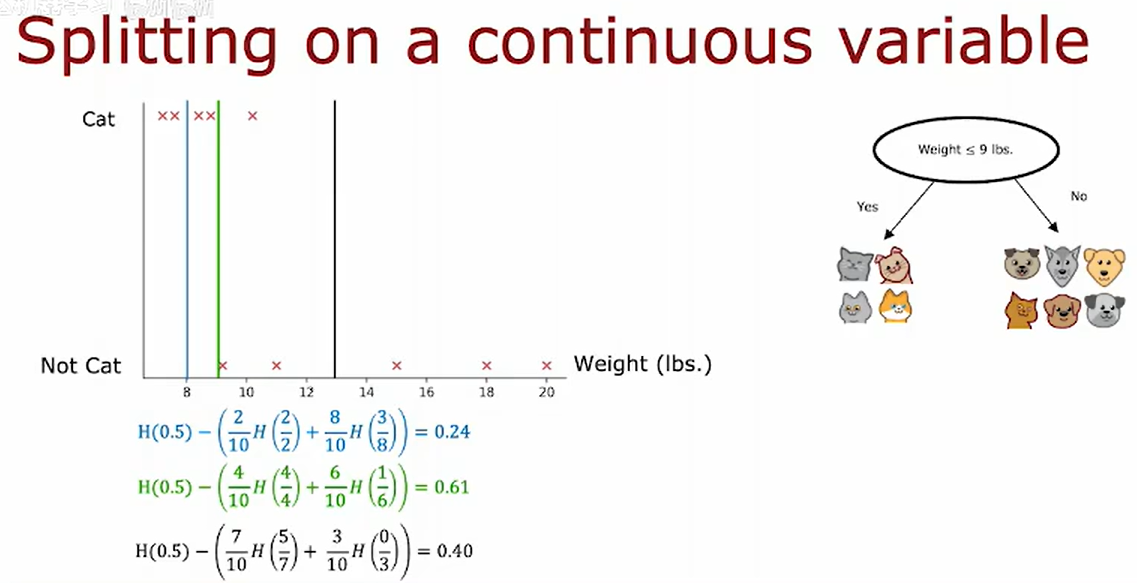
为了让决策树在每个节点处理连续数值特征时能够进行分割,只需要考虑不同的值进行分割,进行常规的信息增益计算,然后选择能够提供最大的可能信息增益的特征值。
回归树
引入各动物的重量(weight)
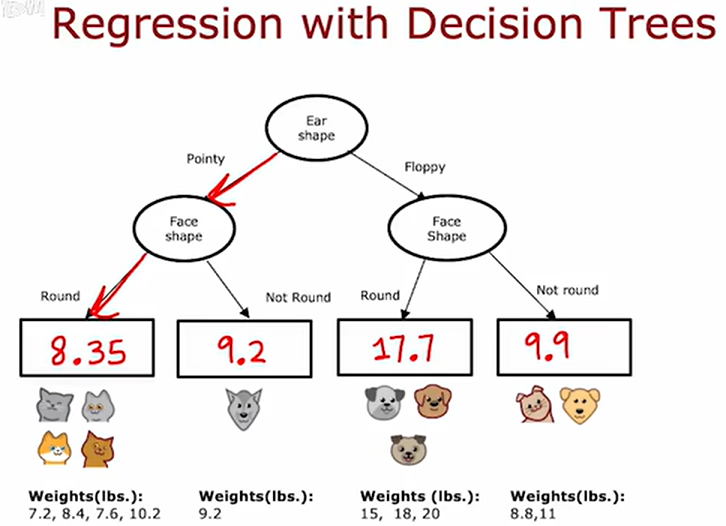

选择分割特征的一种好方法是选择加权方差最低的值。
使用多个决策树
树集成(tree ensemble)使算法变得不那么敏感和更加稳健
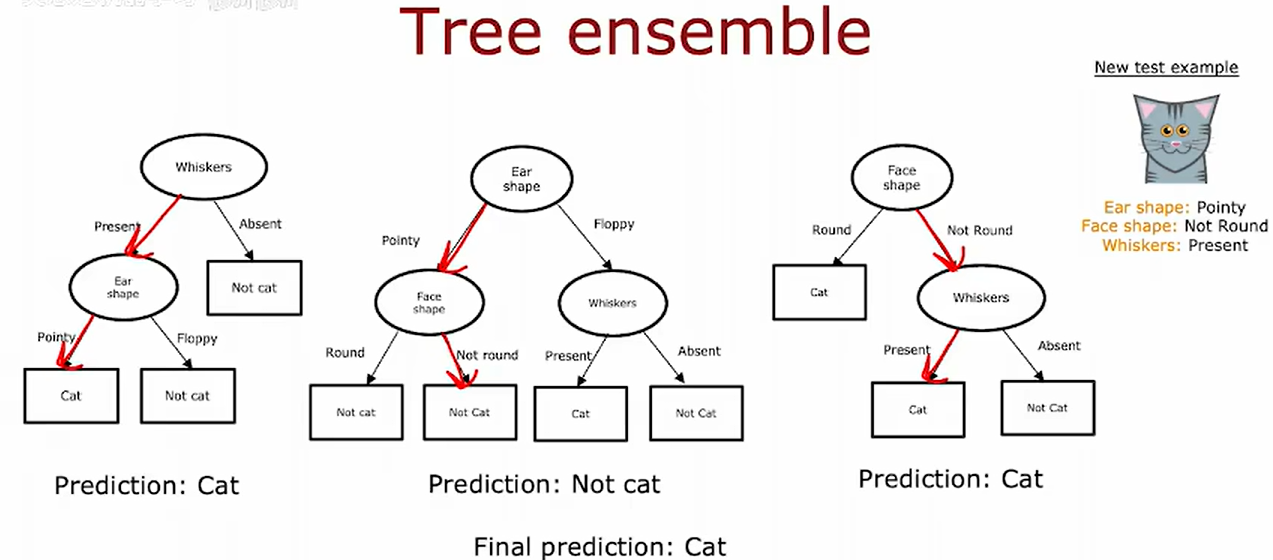
在新样本上运行这三棵树,并让它们对最终预测进行投票,这使得整体算法对任何单颗树的影响变得不那么敏感。
放回抽样是构建树集成的关键构件,用于构建一个与原始数据集不太相同的“新”数据集。
随机森林算法

当B值远大于某个值时会面临收益递减,实际效果不会有明显提升,反而会减慢计算速度。

把袋装决策树转换为随机森林的关键思想:在每个节点随机化特征选择,这种技术往往更多用于具有大量特征的更大问题,这探索并平均了训练集的许多小变化
k的一个典型选择时选择$\sqrt(n)$
XGBoost

以更高的概率选择那些在目前构建的树集合中表现较差(分类出错)的样本

XGBoost不需要生成大量随机选择的训练集,比有放回采样程序更高效
什么时候用决策树

决策树和集成树作用在表格化(结构化)数据上效果更好
决策树和集成树运行速度更快
可以用梯度下降方法同时训练多个串联的神经网络,而决策树一次只能训练一个