卷积神经网络
1.2 边缘检测示例
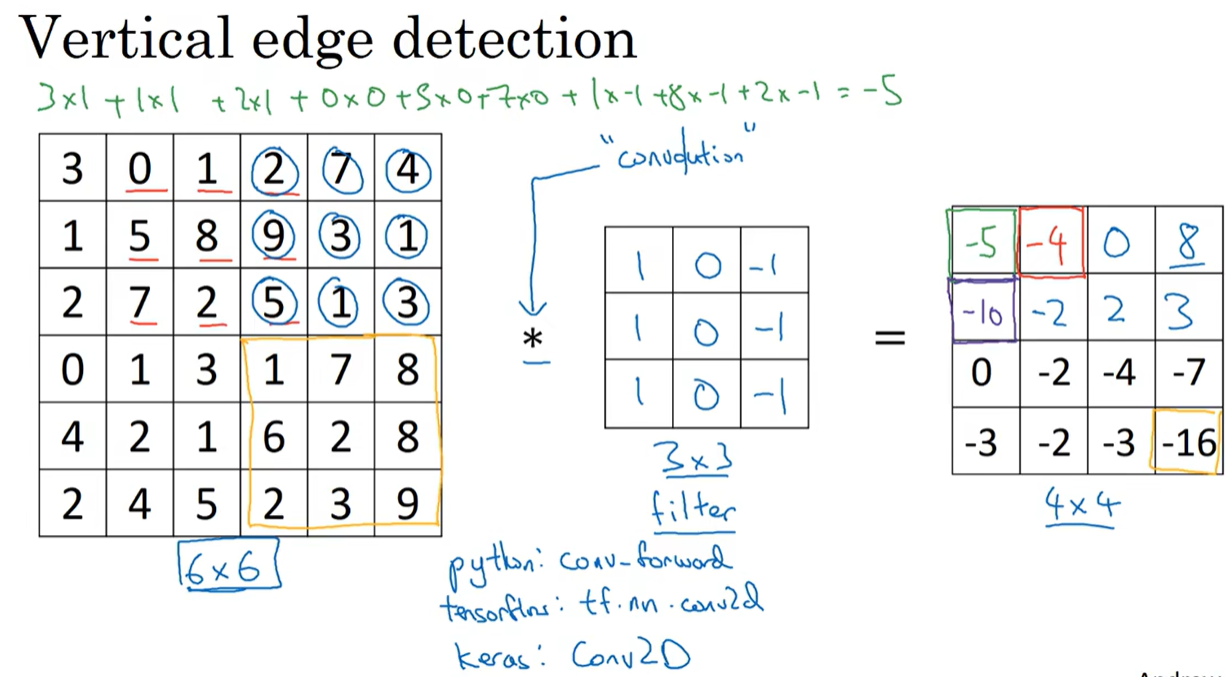
示例中为灰度图像,所以图片维度为(6,6,1)
1.4 Padding
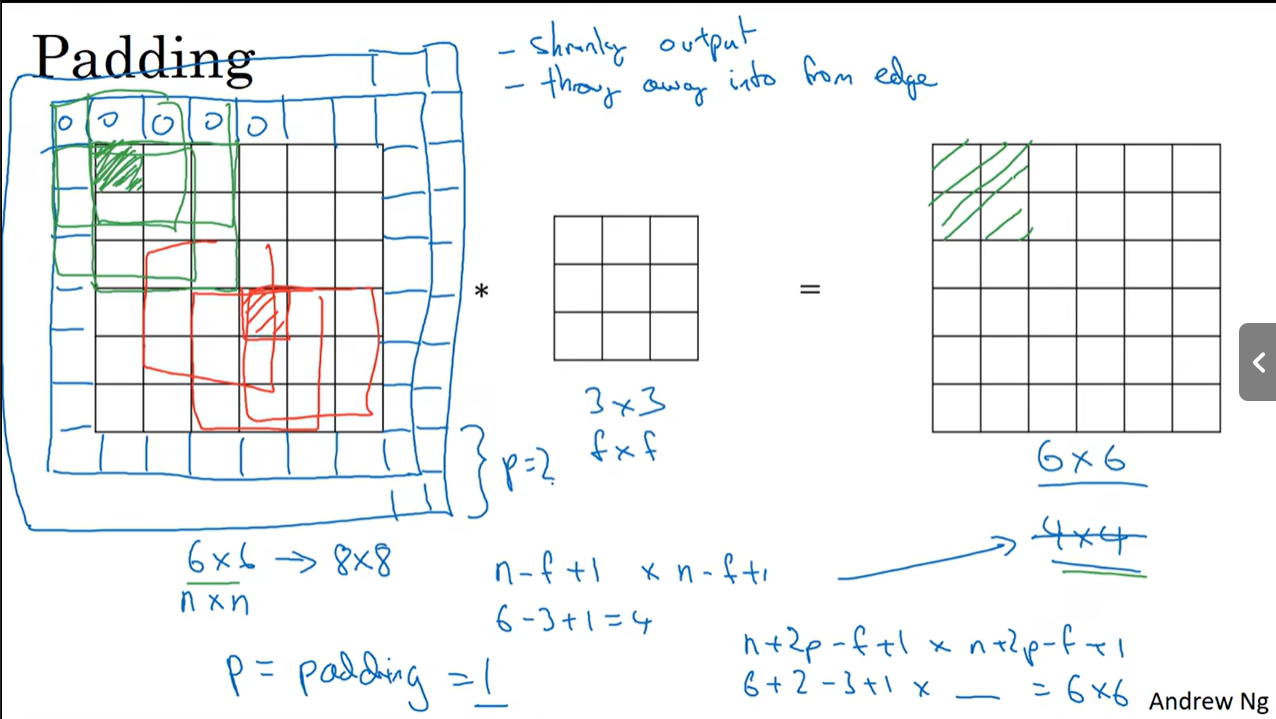
在边缘填充像素,padding为填充的像素层数

当$p=\frac{f-1}{2}$时输出的图像大小和原图像大小一样,f通常是奇数,推荐只用f为奇数的过滤器
1.5 卷积步长
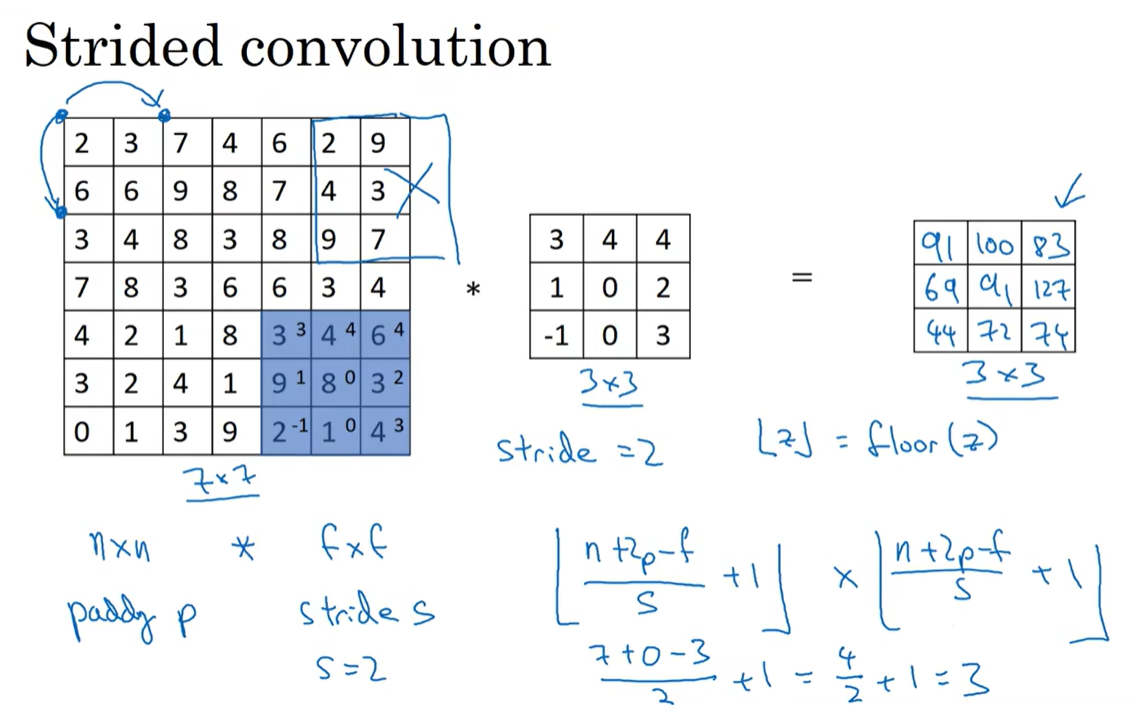
目标矩阵为$n\times n$,内核大小为$f \times f$,padding为p,strides为2,则卷积得出的矩。阵大小为$(\llcorner\frac{n+2p-f}{s}+1\lrcorner) \times (\llcorner\frac{n+2p-f}{s}+1\lrcorner)$,其中对结果进行向下取整。
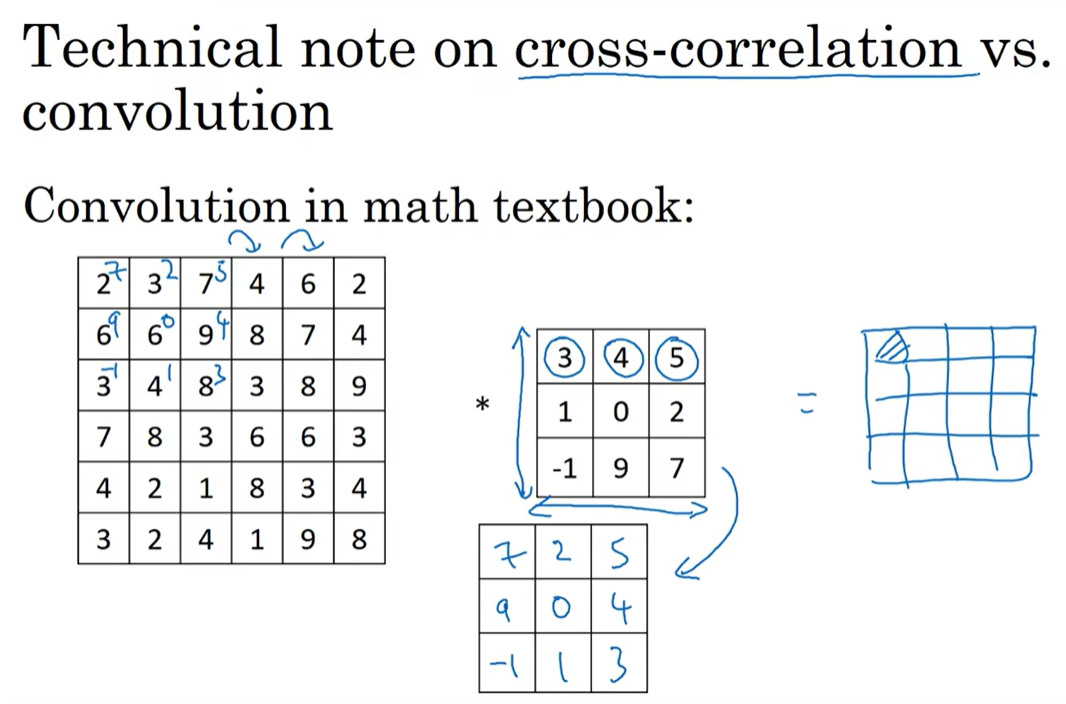
数学教科书中的卷积运算在进行之前要先将内核矩阵根据负对角线进行翻转然后才继续操作。
计算机的卷积运算在数学层面上叫做互相关,不需要进行翻转。
1.6 三维卷积
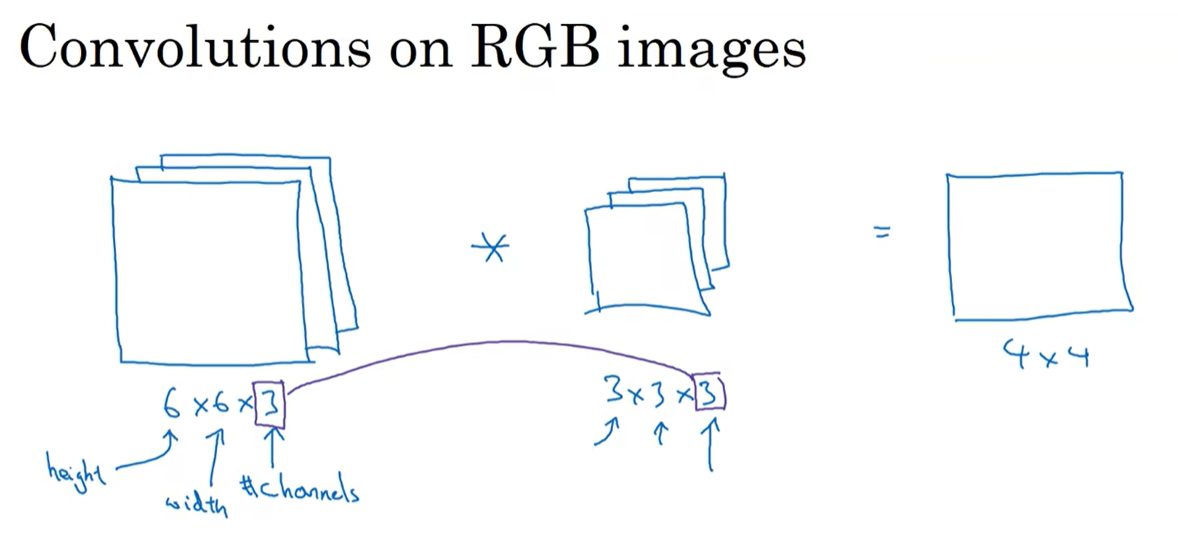
对应RGB的通道数,过滤层也有三个通道。图像的通道数必须和过滤器的通道数相等。
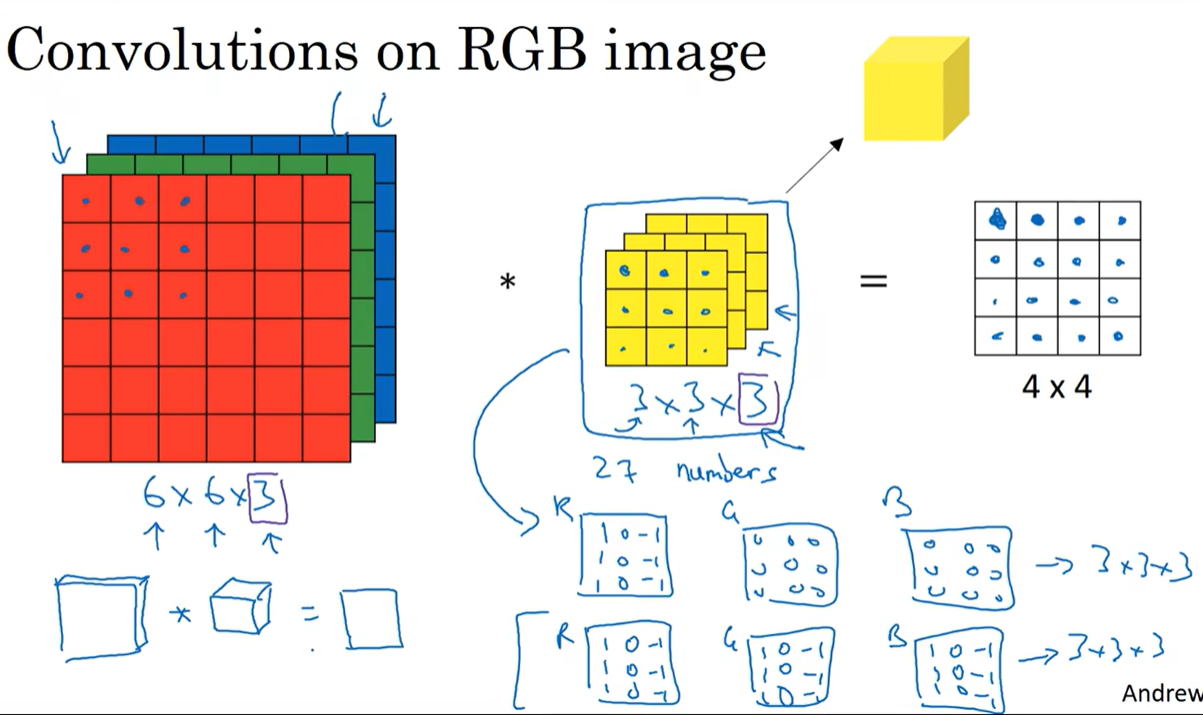
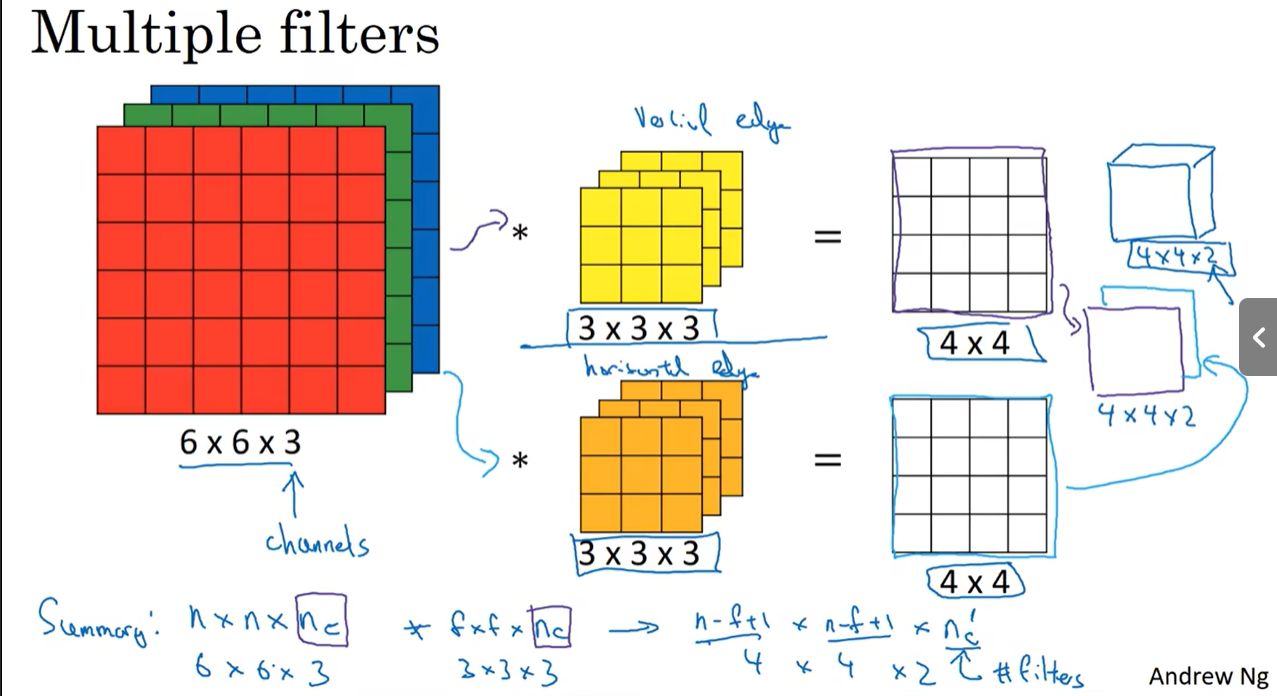
当想要同时检测多个边缘,即需要使用多个过滤器同时检测多个特征时:
上图中为同时使用多个过滤器,其中$n_c$为图像的通道数,$n_c’$为需要检测的特征数,即过滤器的数量。
1.7 单层卷积网络
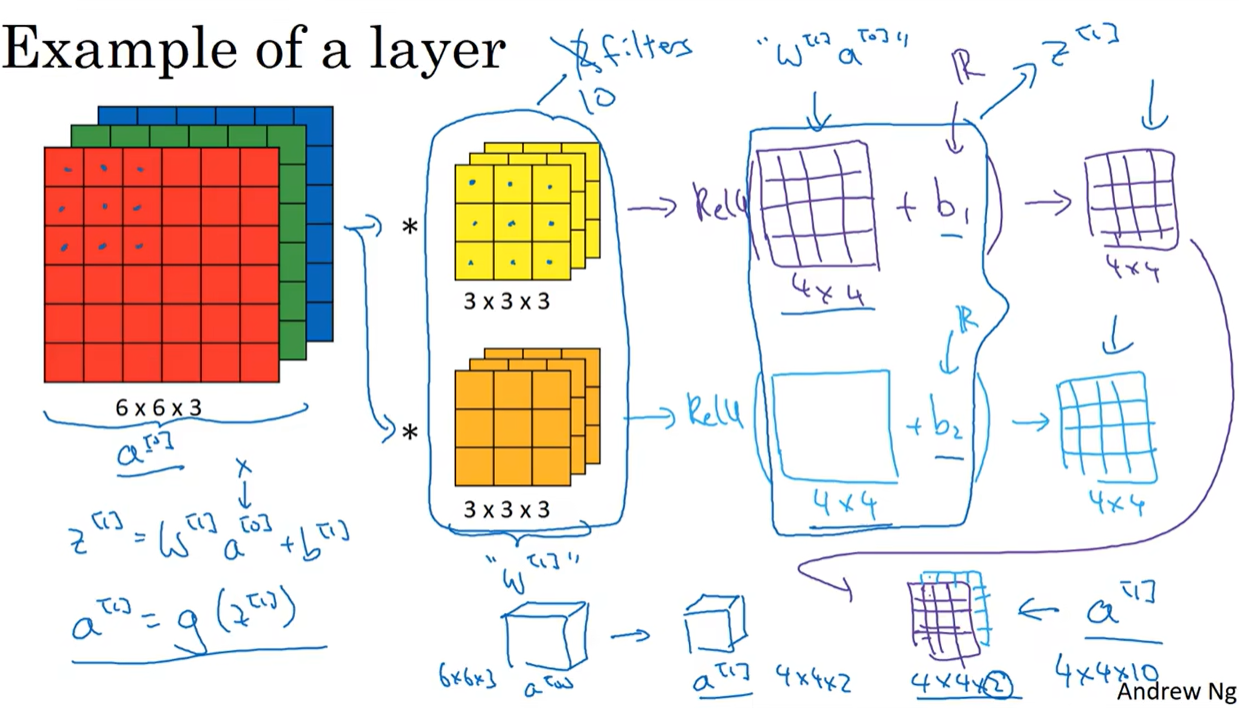
用变量$W^{[1]}$表示两个过滤器。


上图为单层卷积神经网络中每一层的参数。
激活值$A^{[l]}$的维度中的m为输入的样本的数量。
1.8 简单卷积网络示例

随着卷积神经网络深度的加深,图像的高和宽逐渐减小,通道数逐渐增大。
1.9 池化层
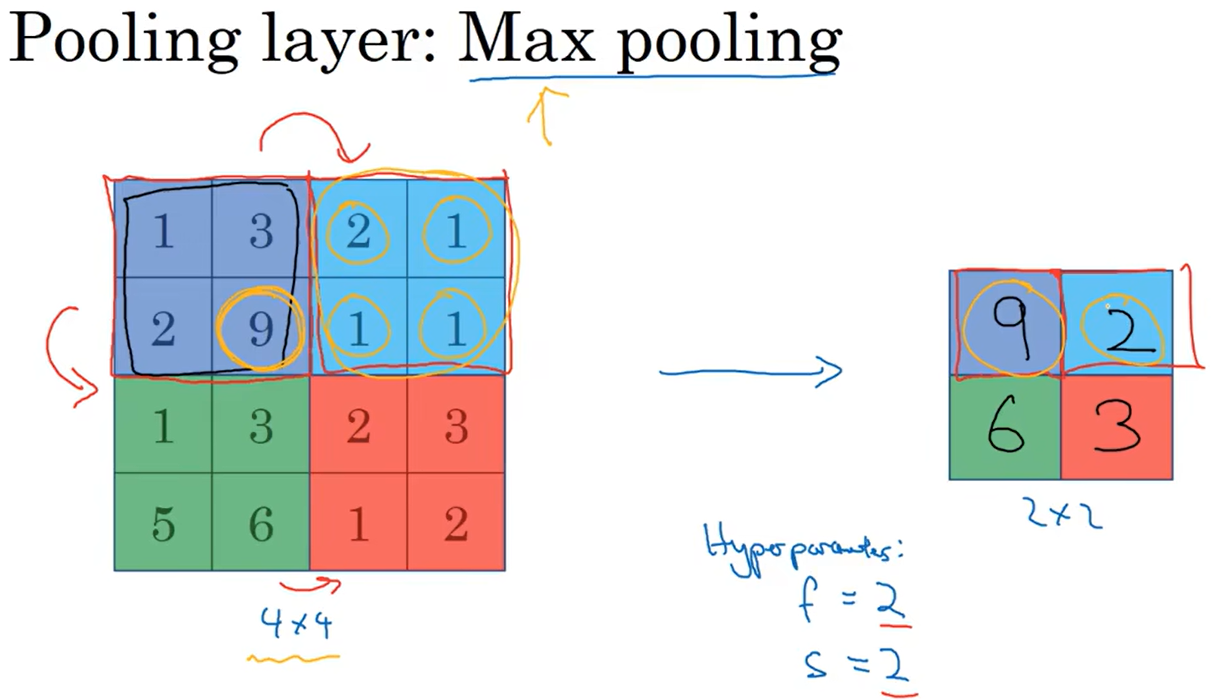
最大池化:
输出的每个元素都是其对应颜色区域中的最大元素值。
这种机制能够有效地原因在于,在发现一个特征之后,它的精确位置远不及它和其他特征的相对位置的关系重要。
池化层会不断地减小数据的空间大小,因此参数的数量和计算量也会下降,这在一定程度上也控制了过拟合。
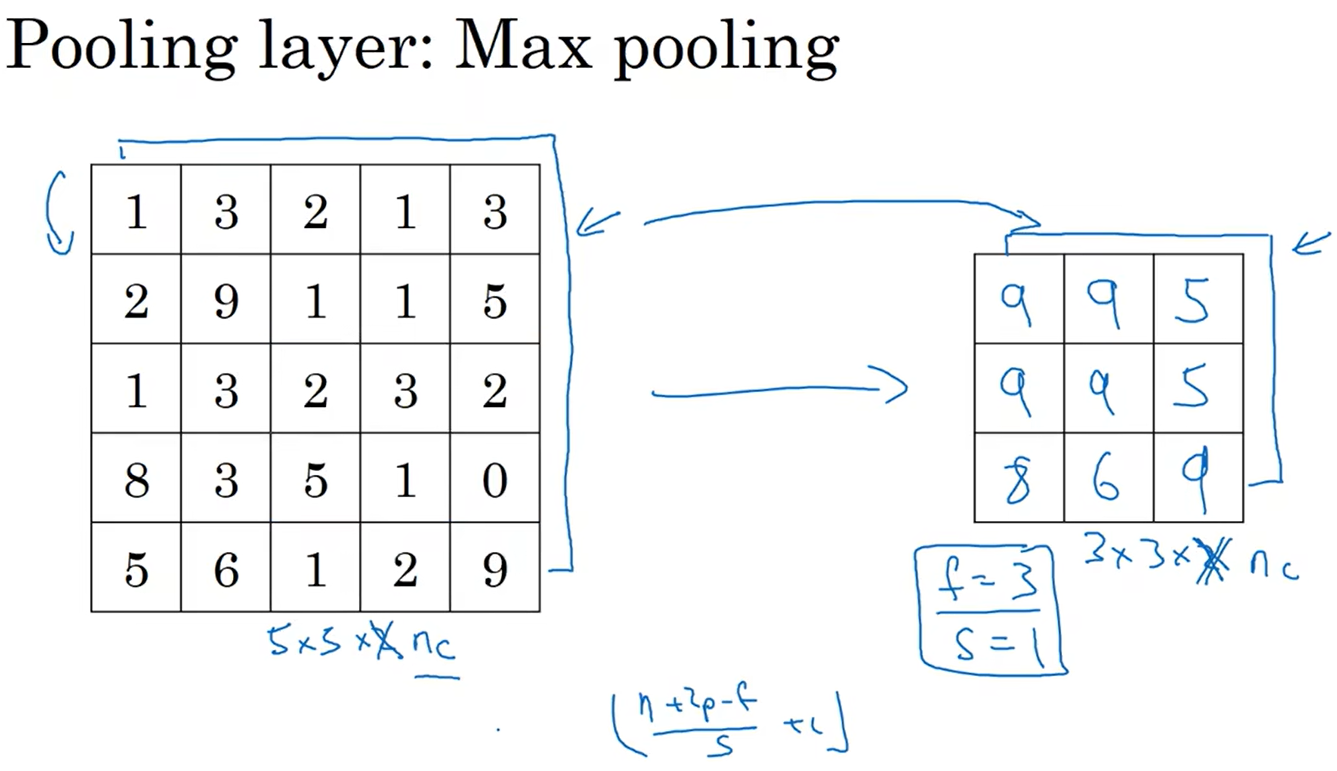
$n_c$个通道中的每个信道都单独执行最大池化计算。
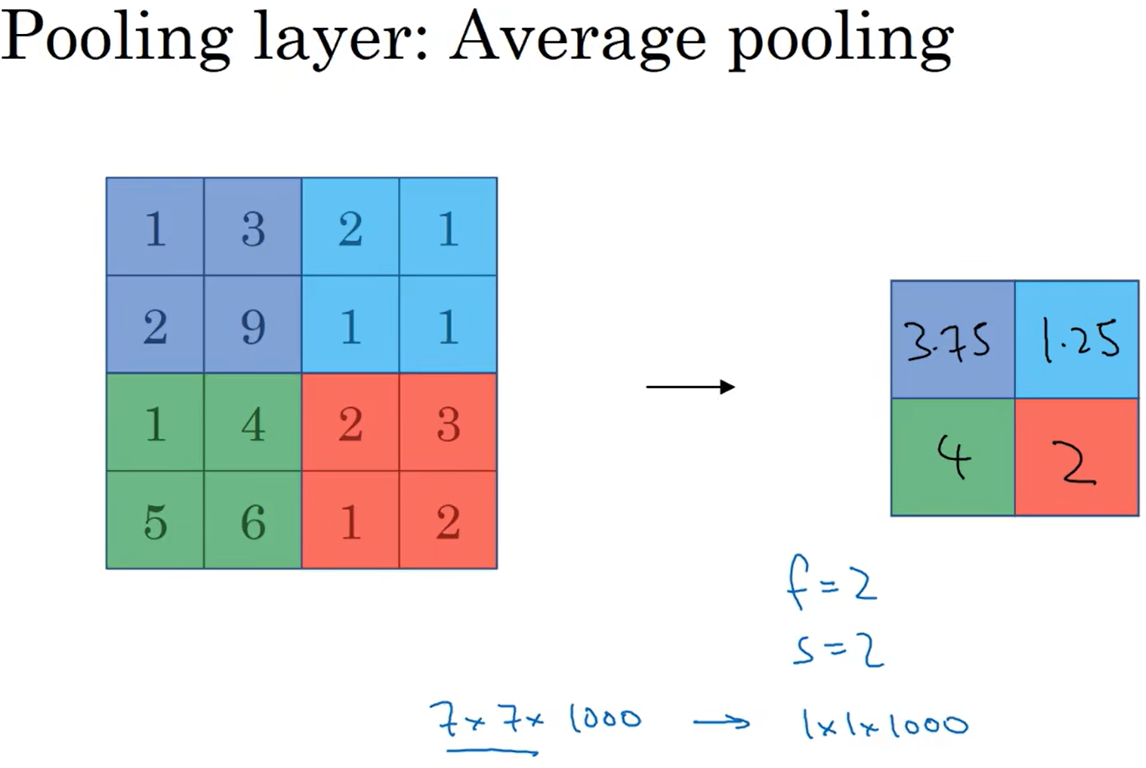
上图为平均池化,最大池化比平均池化更常用。
常用参数为$f=2$、$s=2$,效果相当于高度和宽度缩减一半,最大池化很少用到padding,通常为$p=0$。
池化过程中没有需要学习的参数,它只是神经网络在某一层中用于计算的固定的数学函数。
1.10 卷积神经网络示例
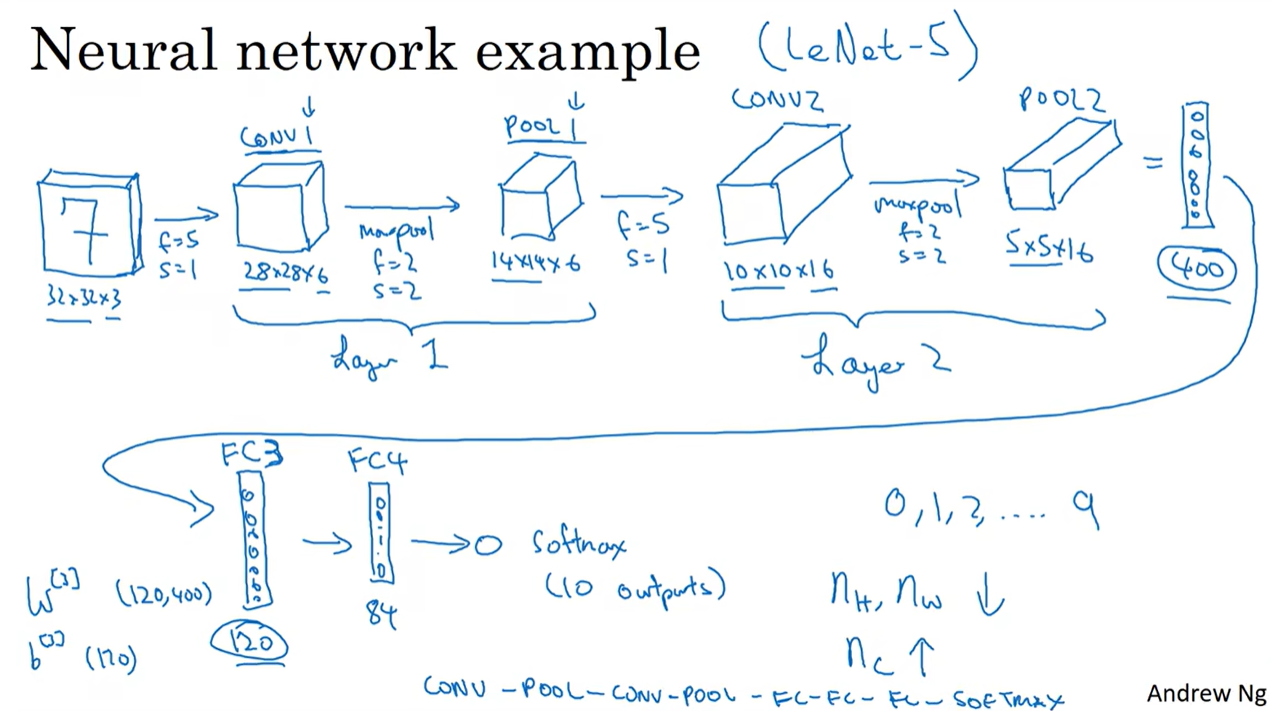
把有权重参数的看作一个layer,所以图中把卷积层(过滤层有权重参数)和池化层(池化层无权重参数)合并看做一个layer。
当f=2且s=2时,高和宽均转换为原来的一半。
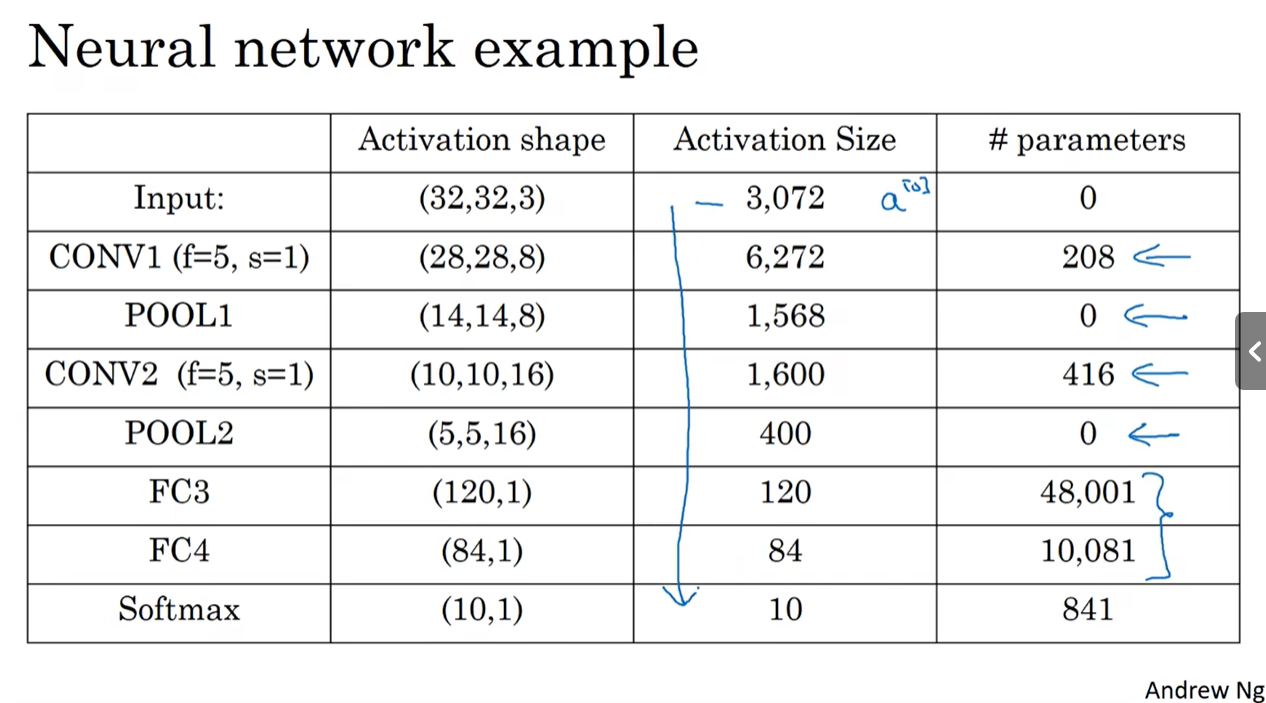
随着神经网络的加深,激活值逐渐变小。如果激活值下降太快,也会影响网络的性能。
1.11 为什么使用卷积
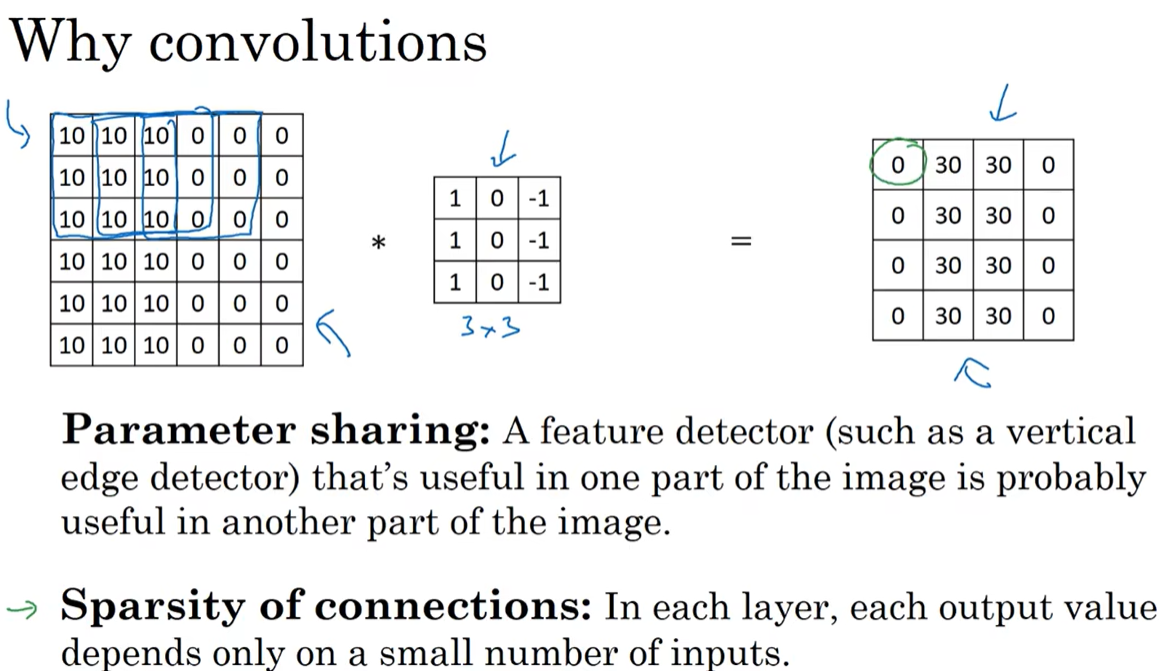
卷积相比于全连接的优点:参数共享、稀疏连接
1、参数共享:若该过滤层矩阵对一张图片提取特征有效,那么它对另一张图片的特征提取也可能有效。
2、稀疏连接:如上图中,输出的矩阵中的每个输出的元素仅仅依赖于输入图像的3*3矩阵,即只依赖9个特征便输出了一个元素。
卷积神经网络通过这两种机制减少了参数,以便用更小的训练集来训练模型。
2.1 为什么要进行实例探究

2.2 经典网络
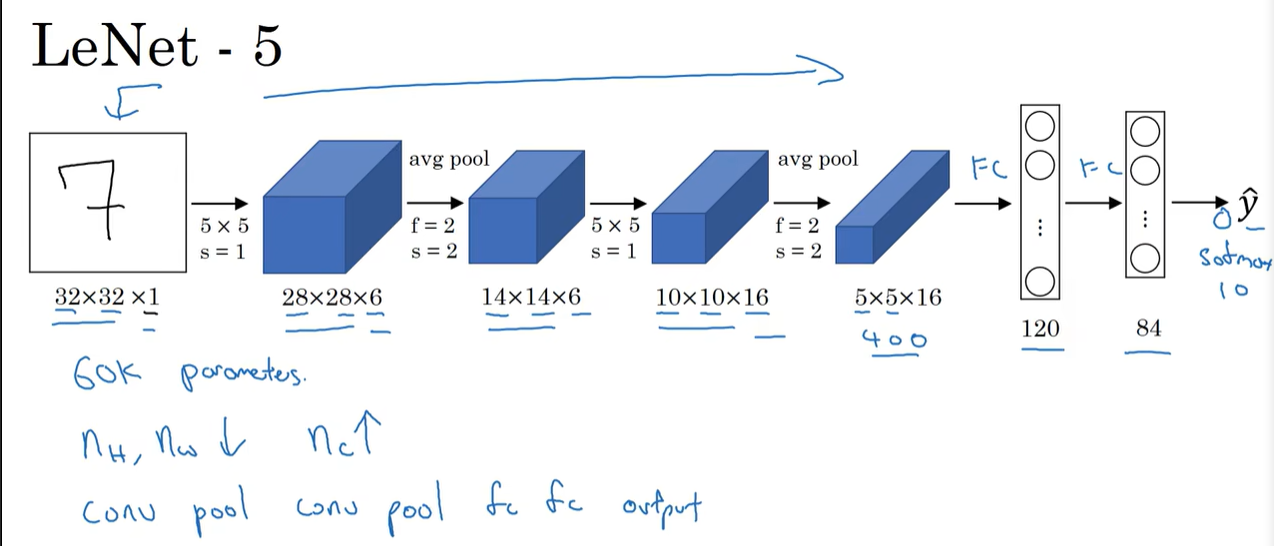
LeNet
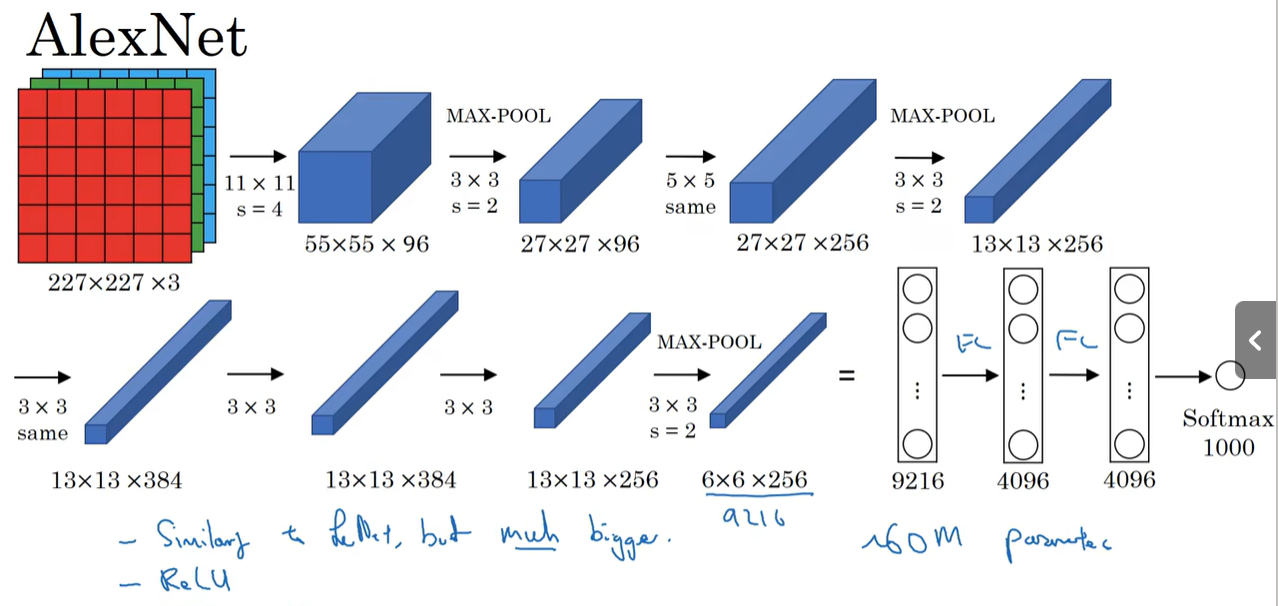
AlexNet
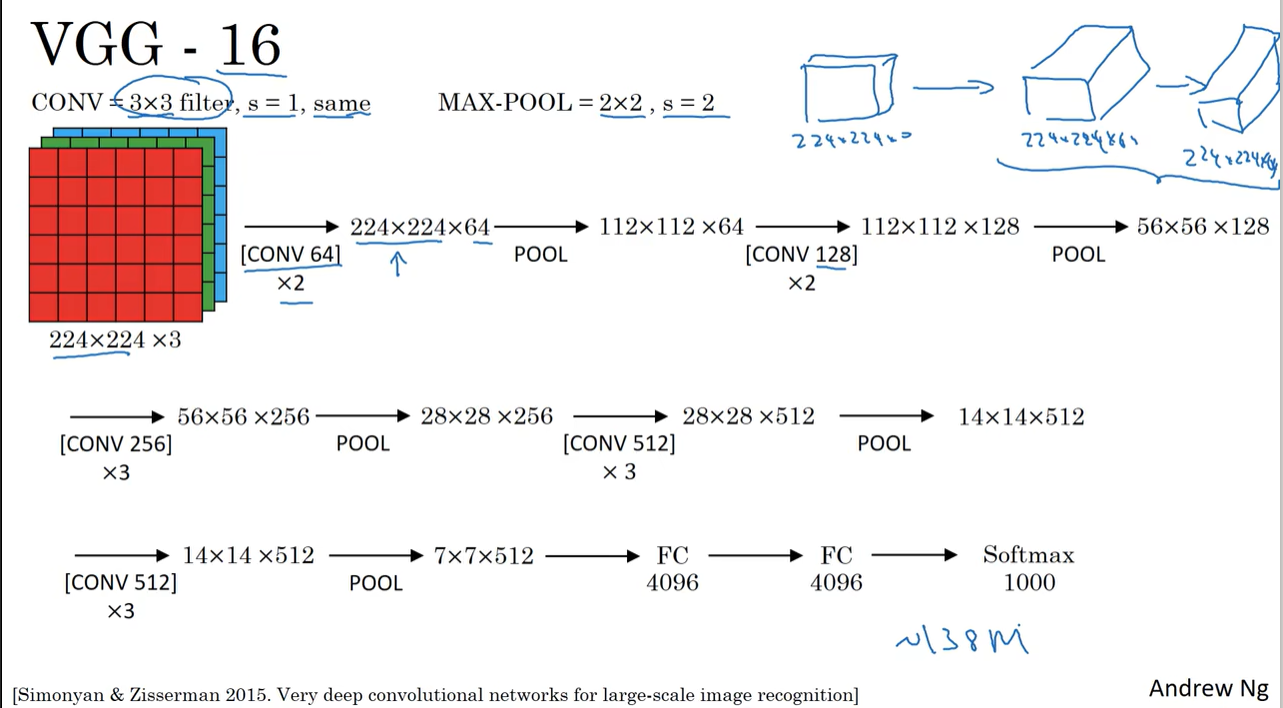
VGG-16:包含16个卷积层和全连接层。图中数字“×2”表示有两个相同的卷积层。
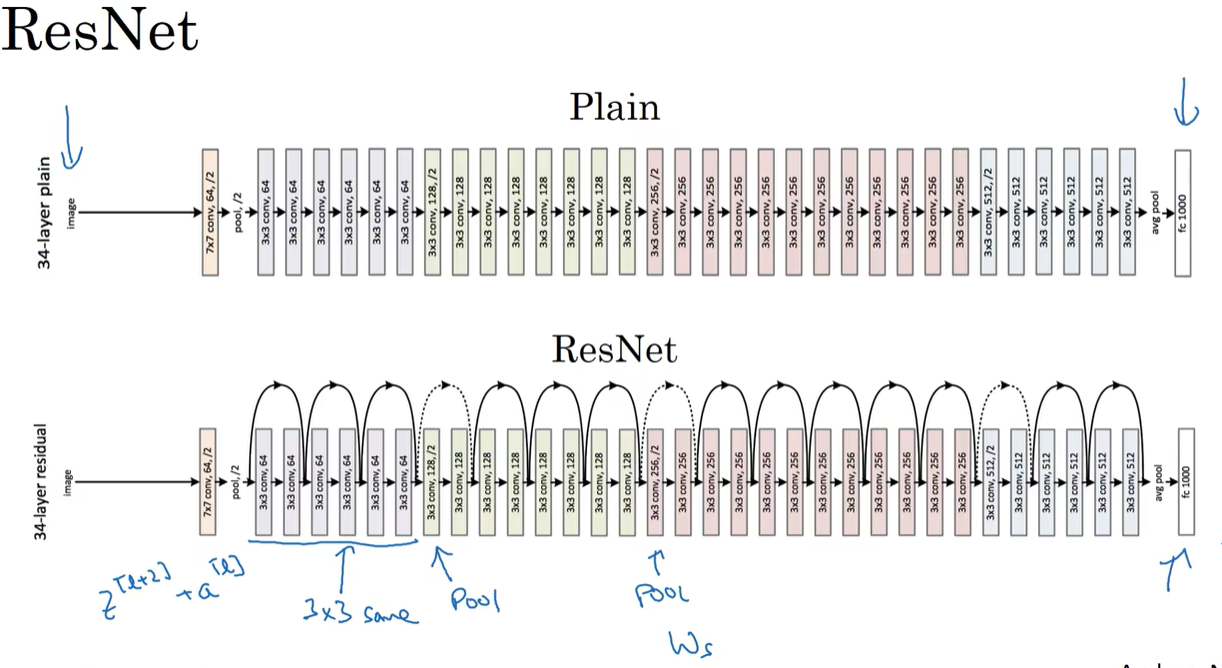
2.3 残差网络(ResNet)
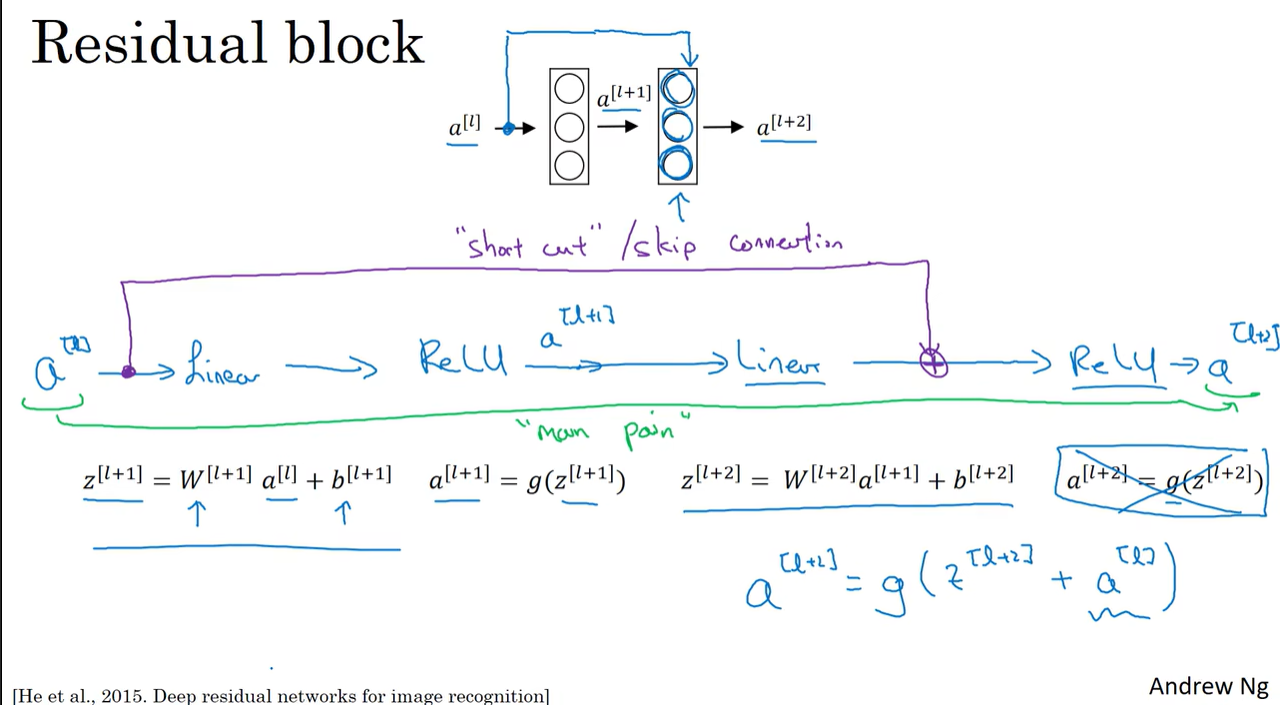
图中的$a^{[l]}$跳过了一层,使得$a^{[l+2]}=g(z^{[l+2]}+a^{[l]})$
远跳连接(skip connection):$a^{[l]}$跳过一层或好几层,将信息传递到神经网络的更深层。
残差块连接在一起构成残差网络
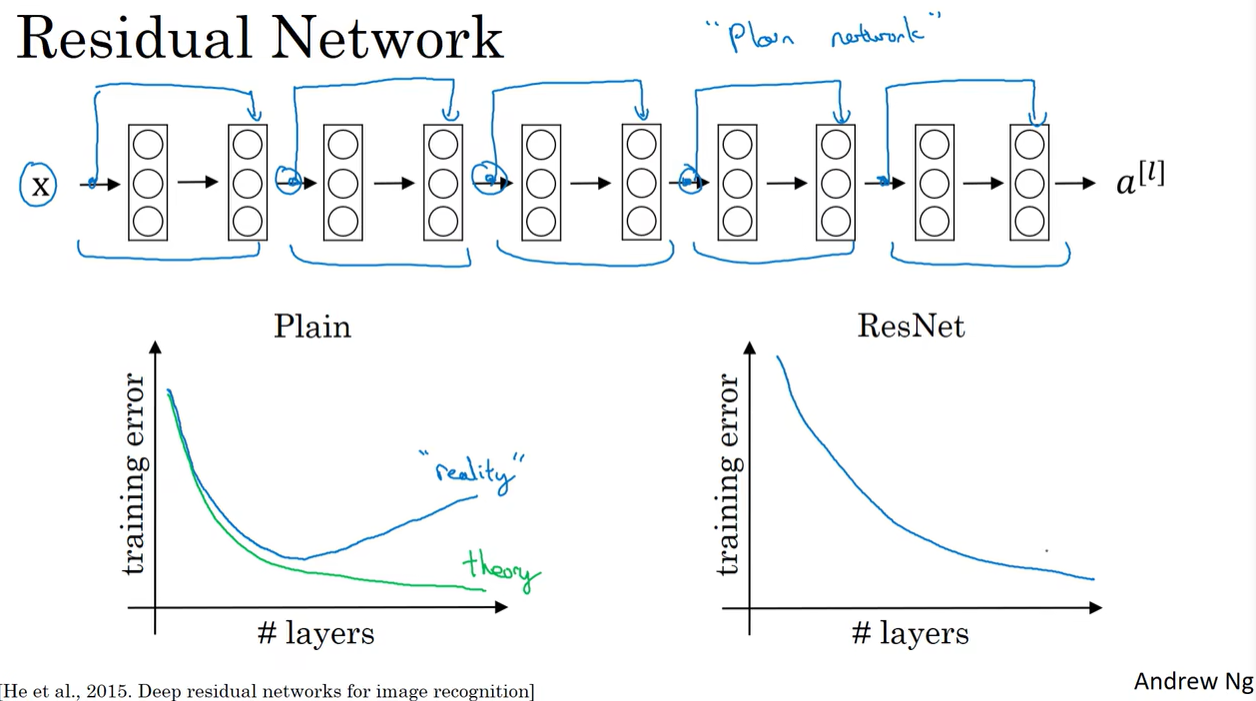
普通的神经网络实际中训练时训练损失随层数的增加先减小后增大,而残差网络的训练损失随层数的增加而不断减小。
2.4 残差网络为什么有用
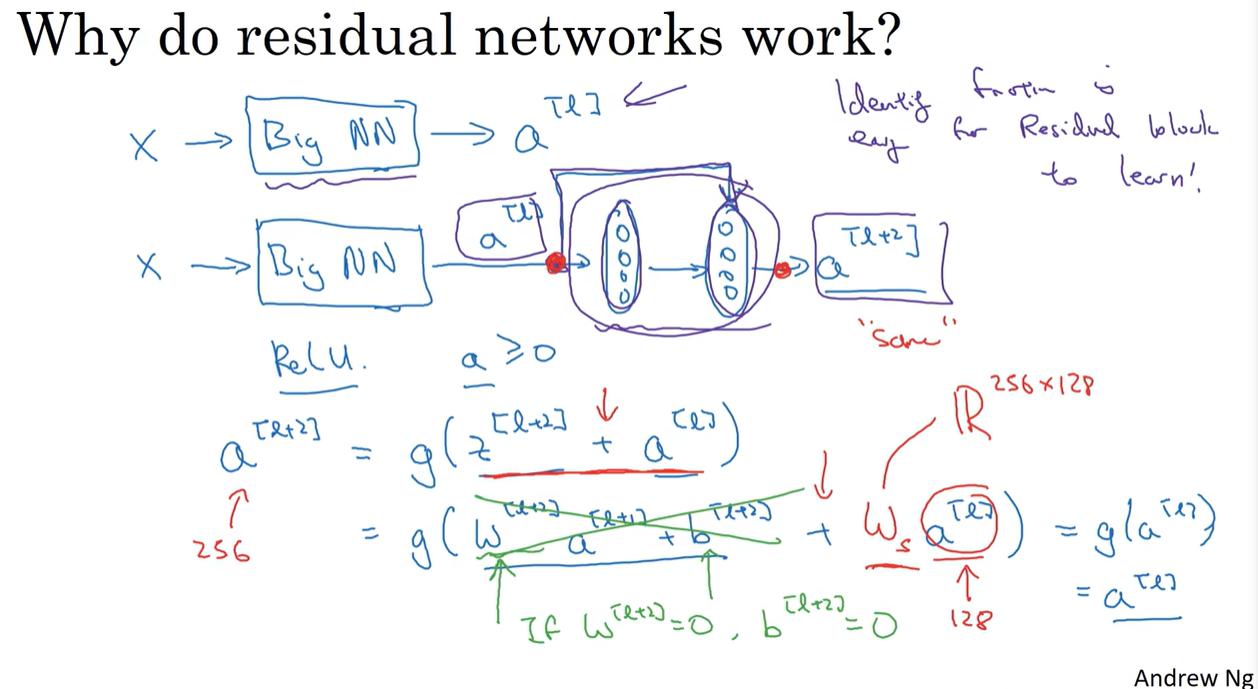
当$W^{[l+2]}$和$b^{[l+2]}$均为0且激活函数为ReLU函数时,$a^{[l+2]}=g(W^{[l+2]}a^{[l+1]}+b^{[l+2]}+a^{[l]})=a^{[l]}$,即次函数为恒等函数。(绿笔部分)
残差网络学习恒等函数比普通网络更容易,能确保随着层数的增加神经网络性能不会受到影响,至少不会降低网络效率,甚至提高效率。
若$a^{[l+2]}$的维度和$a^{[l]}$的维度不一样,可以使用矩阵$W_s$把$a^{[l]}$的维度转换到与$a^{[l+2]}$的一样。无需对$W_s$做任何操作,它是通过学习得到的矩阵参数。(红笔部分)
2.5 网络中的网络以及1×1卷积
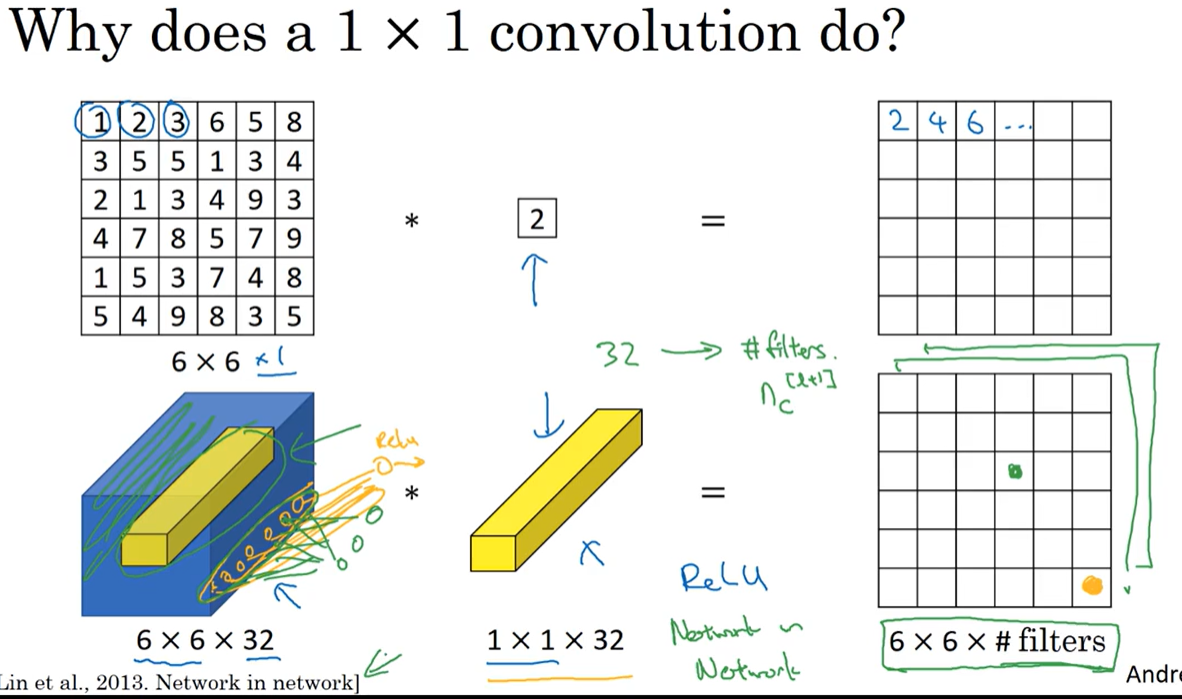
图中黄色表示的过滤层中的32个元素相当于权重,输入的图像中每一个参与卷积的1×1×32矩阵中的每个元素乘上过滤层中的权重进行线性变换再经过ReLU函数(保持不变)后映射到输出的图像中,相当于在网络中还有网络。
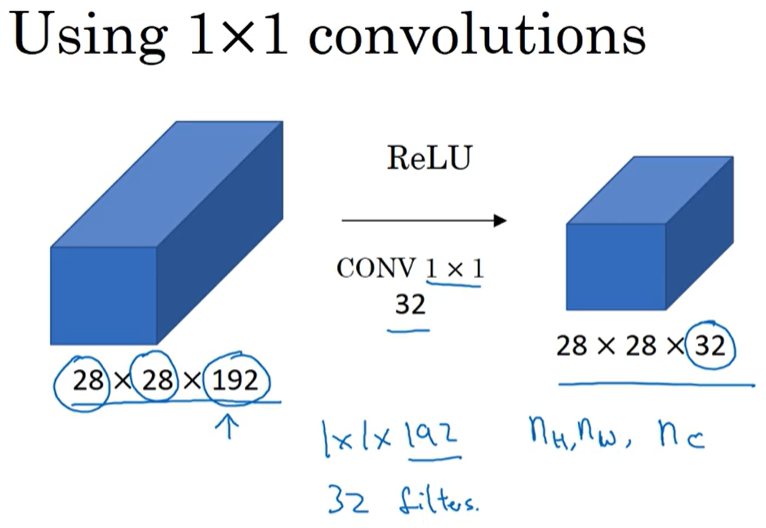
通过1×1卷积的简单操作来压缩或保持输入层中的信道数量,甚至是增加信道数量。
2.6 谷歌Inception网络简介
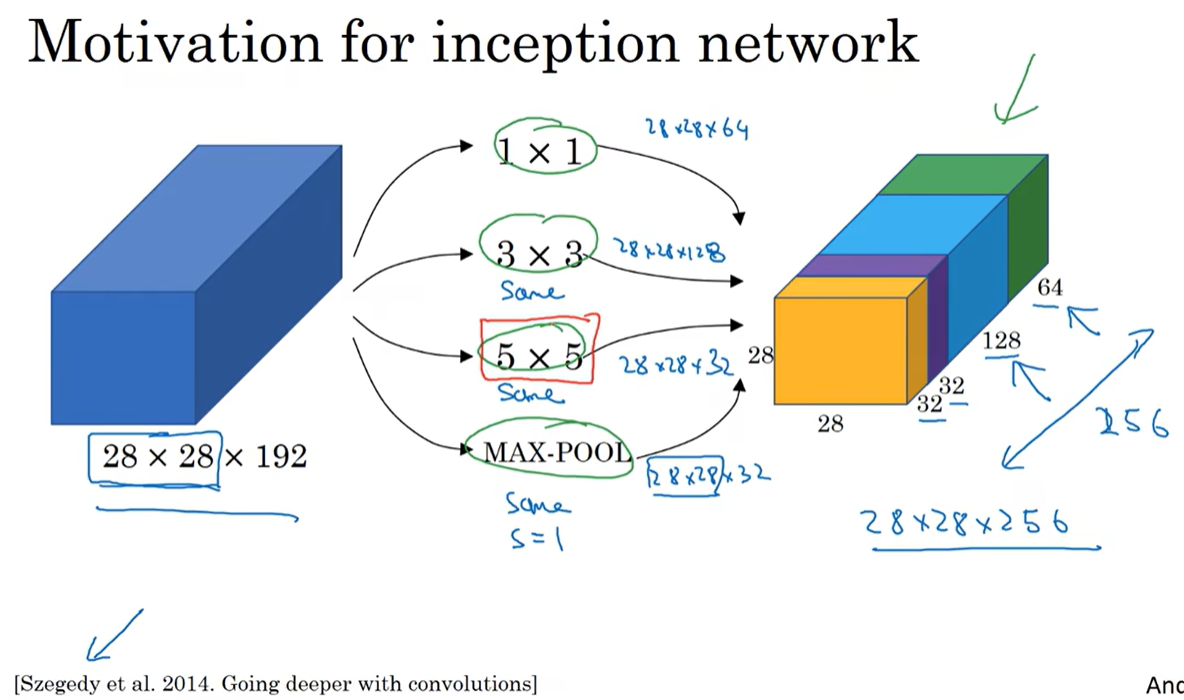
Inception网络不需要决定使用哪个过滤器或是否需要池化,而是由网络自行确定这些参数。可以把参数的可能值给网络,网络自己学习它需要什么样的参数和采用哪些过滤器组合。
上图的高和宽不变是因为使用了padding,图中未标明。
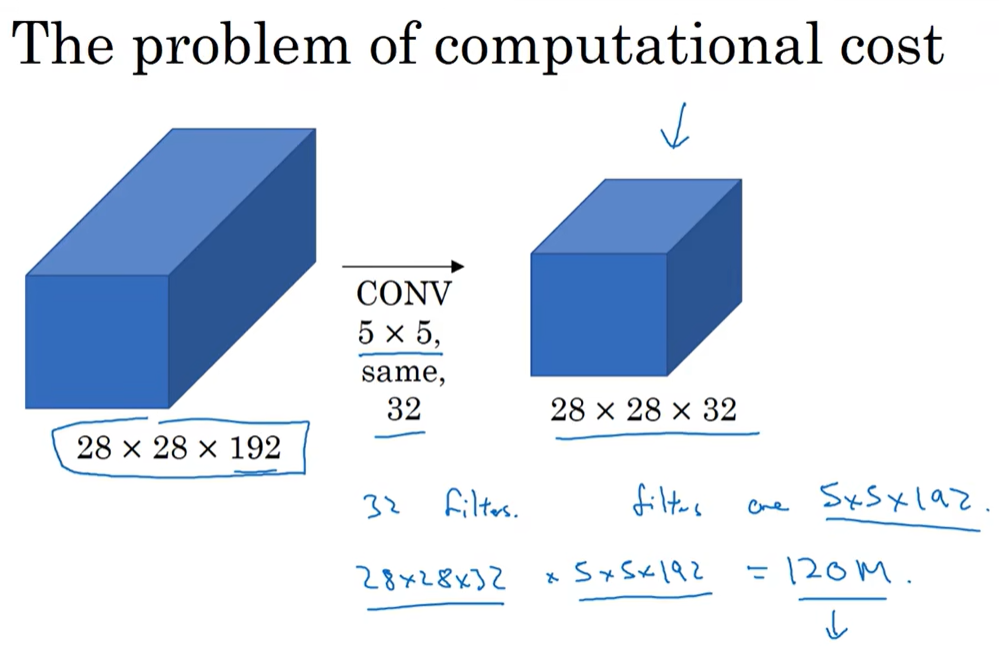
直接进行上图中的卷积运算计算成本大,要进行12亿次运算,可以使用1×1卷积压缩通道数以减少运算次数。
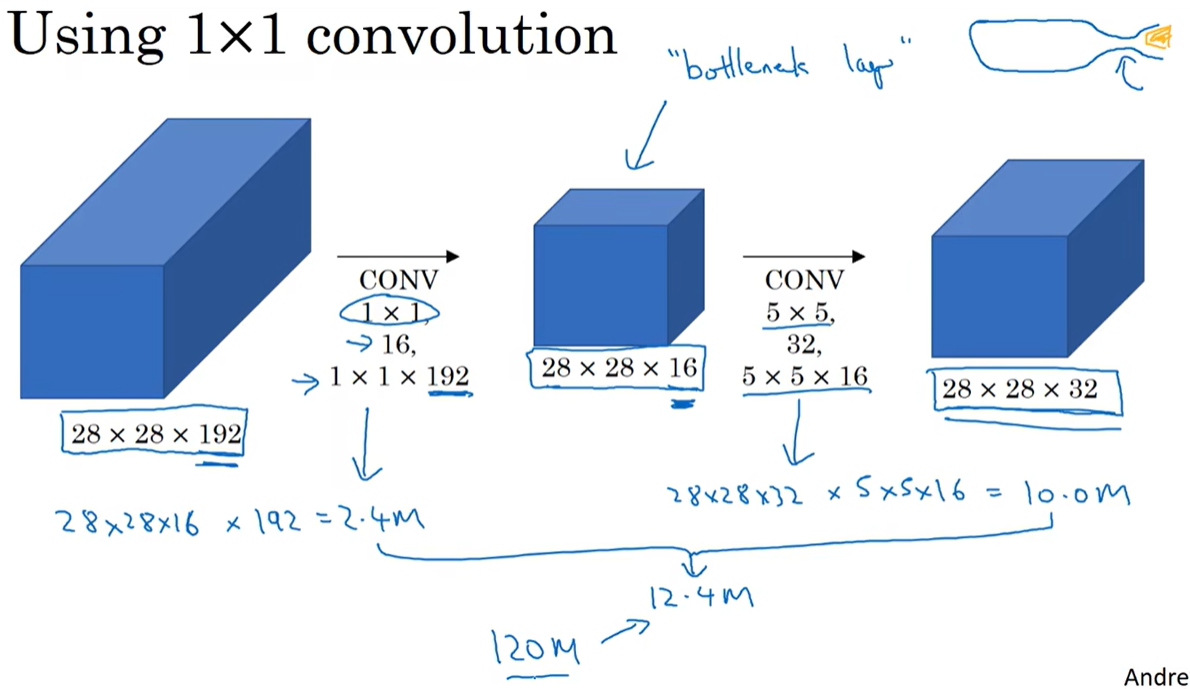
瓶颈层(bottle neck)通常是某个对象最小的部分。
2.7 Inception网络
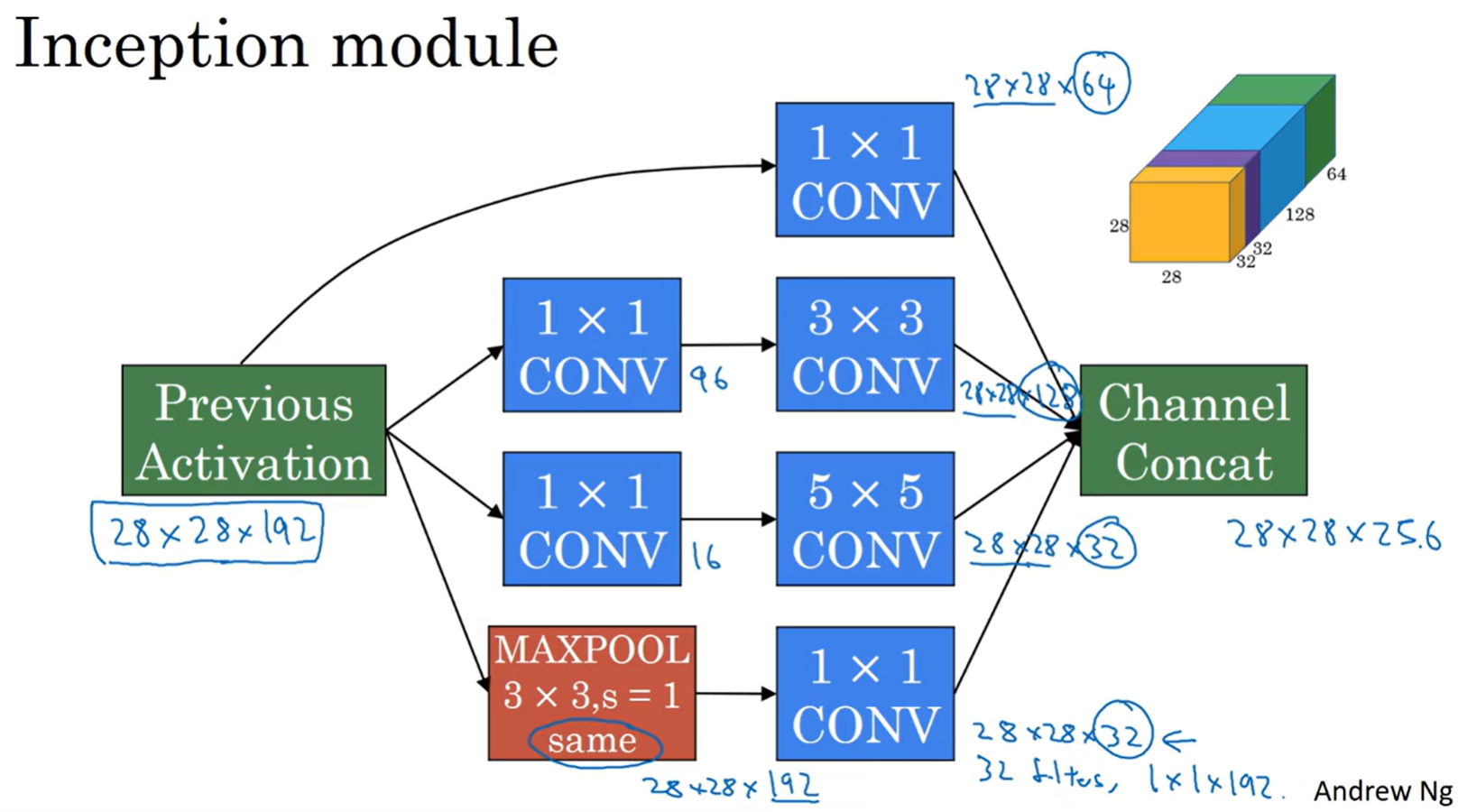
图中的16和96为使用1×1卷积后的图像的通道数。
Channel Concat 就是把所有的输出图像叠加在一起,如图中不同颜色的方块连接在一起。
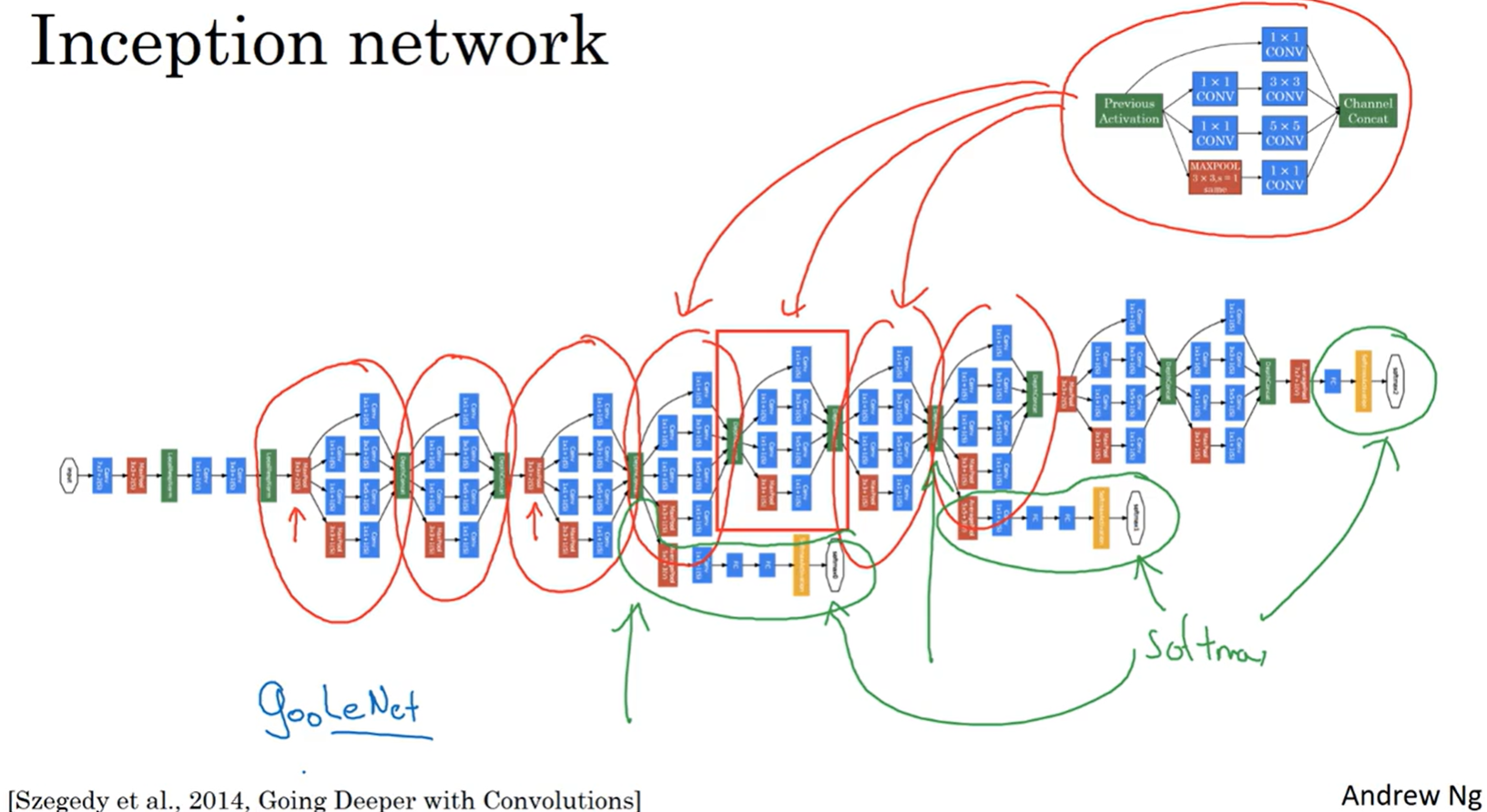
Inception network 是很多 Inception module 一环接一环最后组成了网络。
2.9 迁移学习
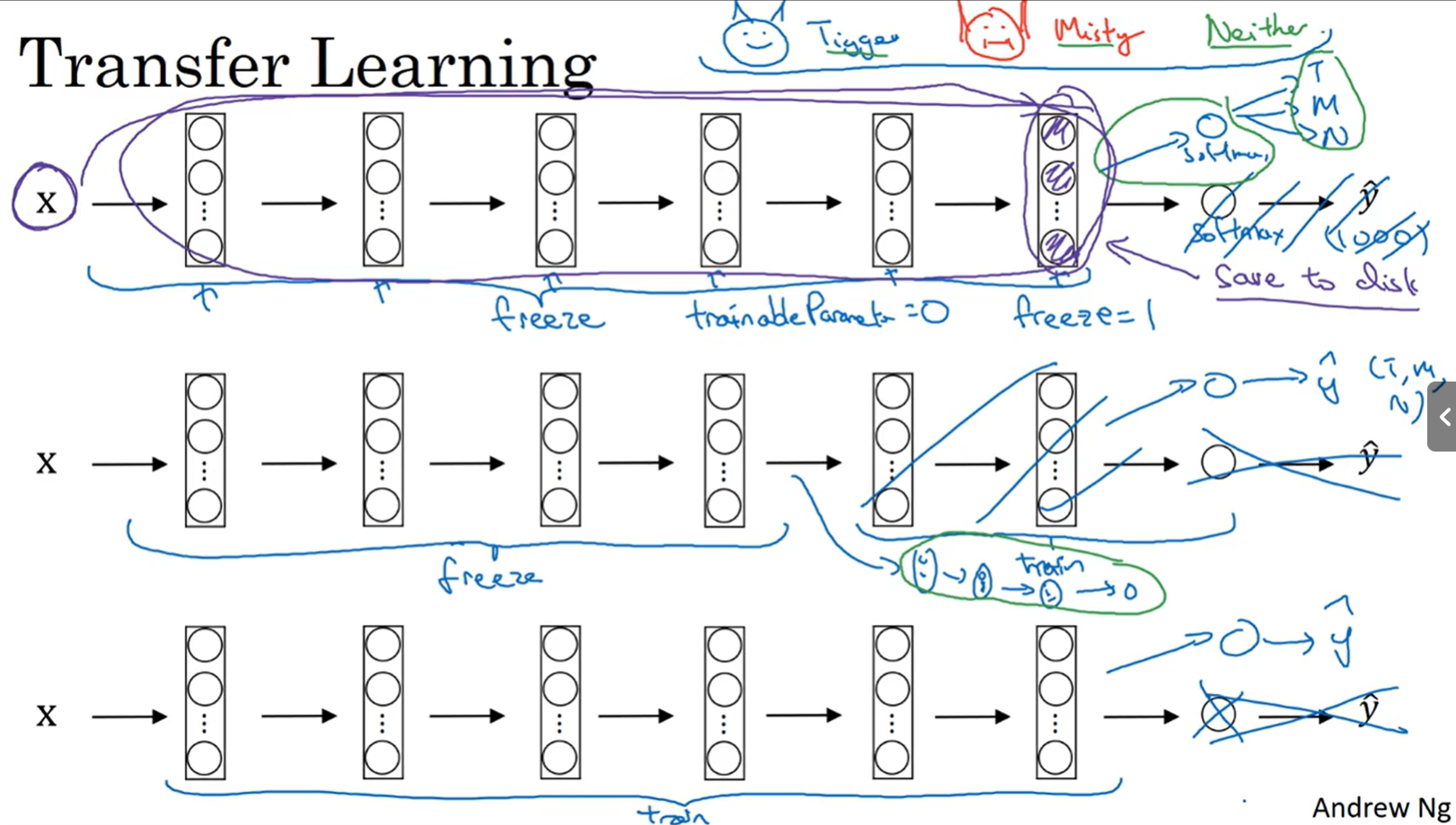
Transfer Learning : 把别人训练得到的公共数据集的知识(weights)迁移到自己的问题上。
可以提前存储前面冻结的网络层的激活值到磁盘中,这样无需每次都遍历整个数据集而是直接使用前面冻结了权重的网络的激活值来对后面要自己训练的网络进行训练。(紫色部分)
通常设置参数trainableParameter=0或freeze=1使得模型不自己学习权重而使用原始的权重(冻结权重)。
自己拥有的数据集越大则能够训练的网络越大,数据集足够大则可把别人的权重当作初始权重,然后使用梯度下降对整个神经网络进行训练。
2.10 数据增强
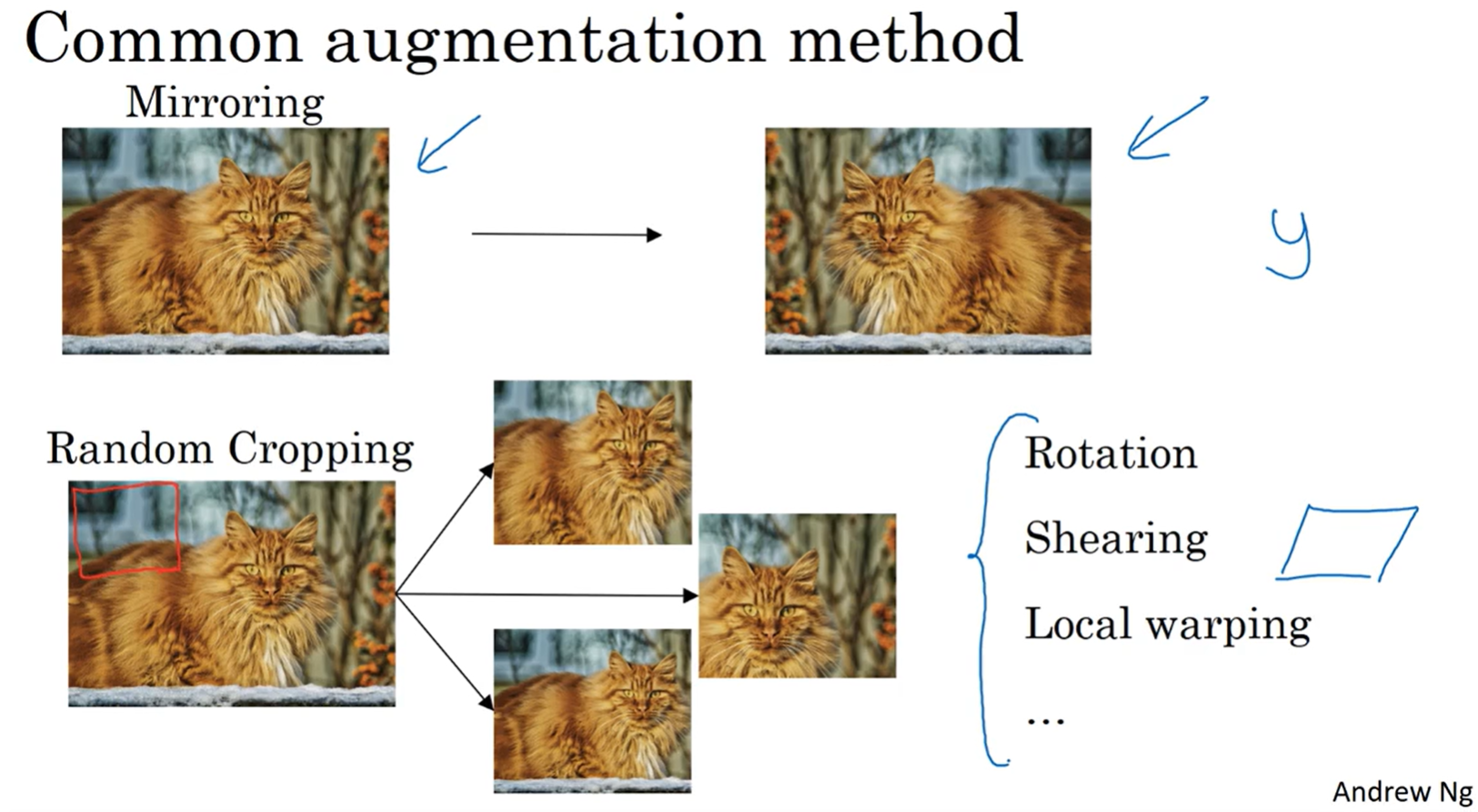
垂直镜像对称、随机裁剪经常被使用,除此之外还有旋转、剪切、扭曲变换等。
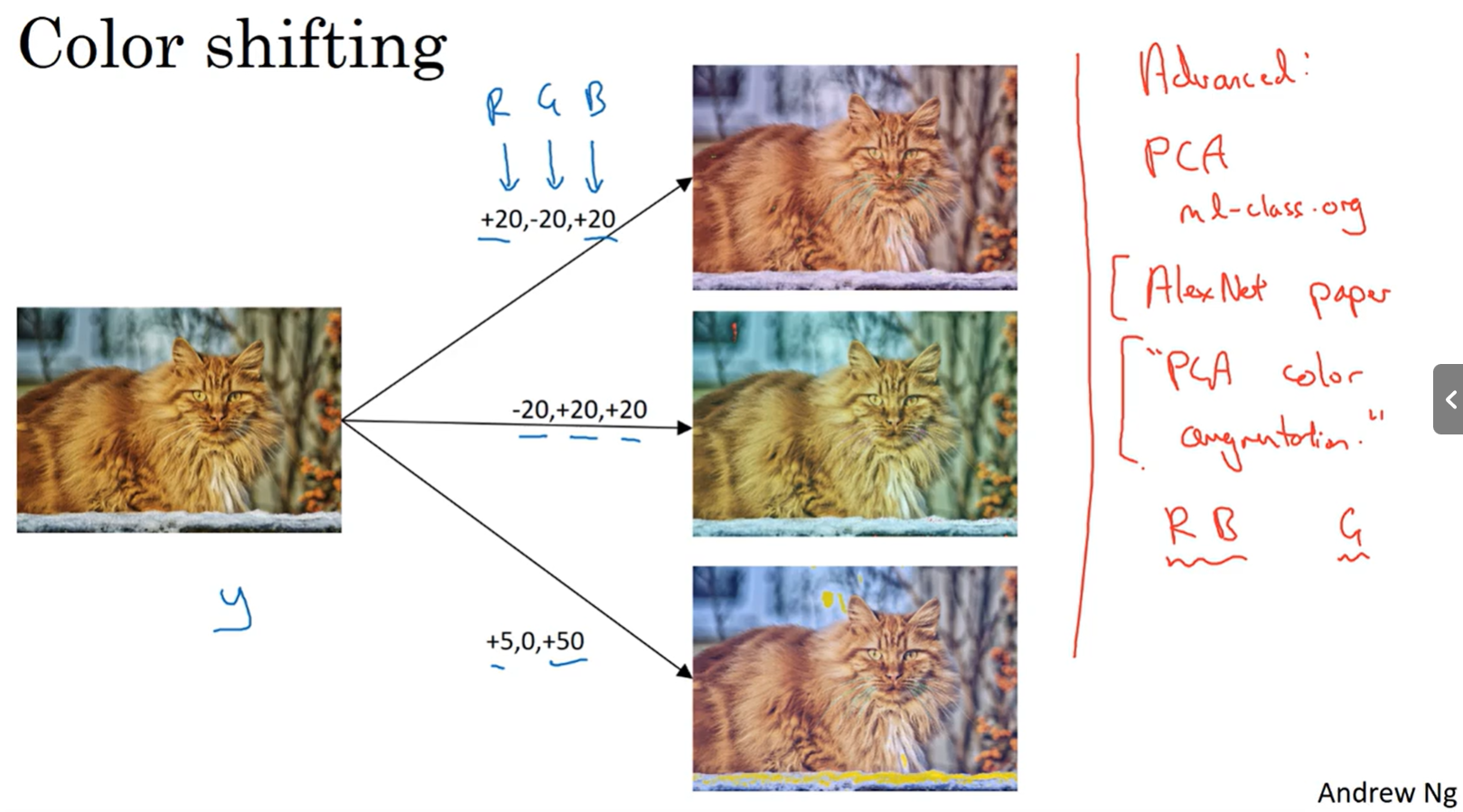
颜色变换,这会使得学习算法对照片的颜色更改更具鲁棒性。
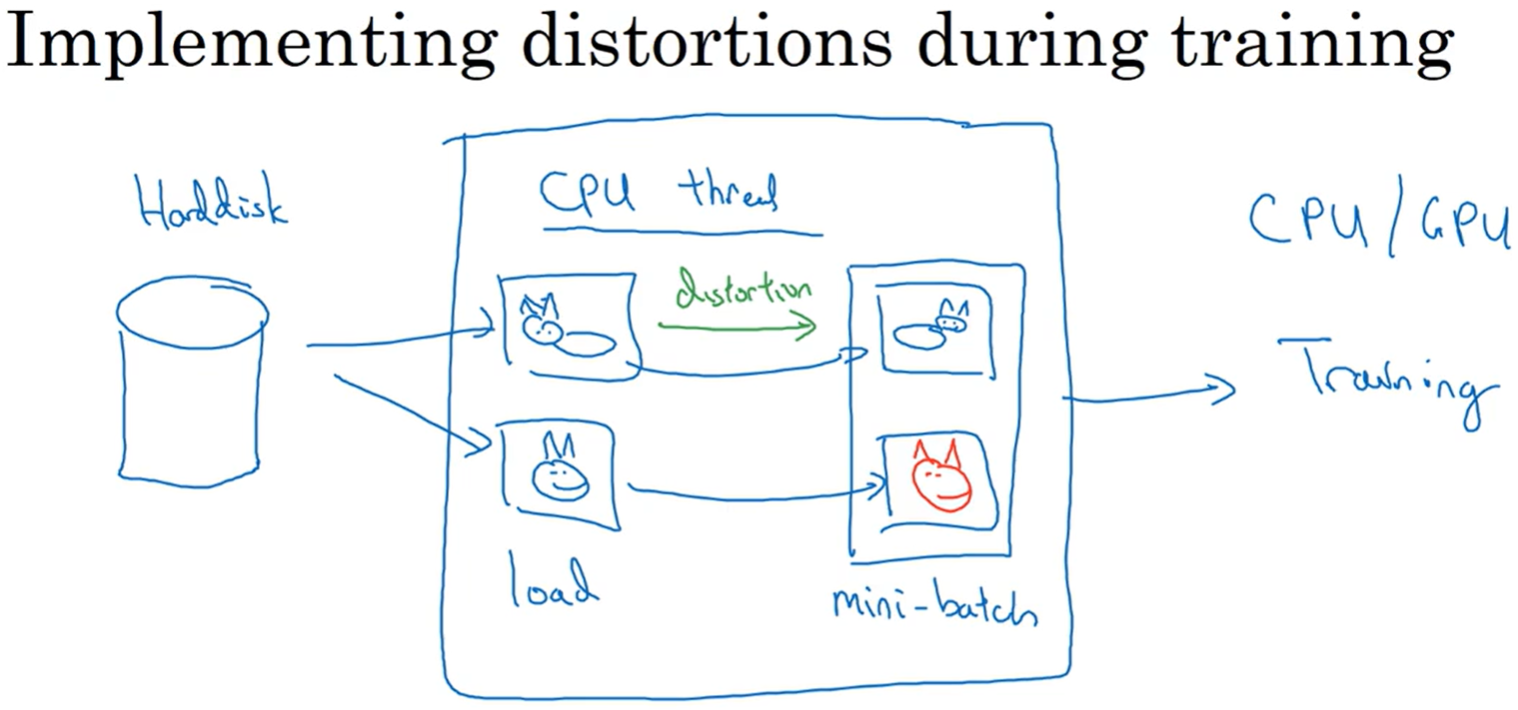
在训练中实现变形:从磁盘读取图像数据,CPU中的一个线程进行图像变形,然后把变形后的图像传输到CPU或GPU的另一个线程上进行训练。图像变形和模型训练可以在不同的线程上并行进行。