注意力机制
注意力提示
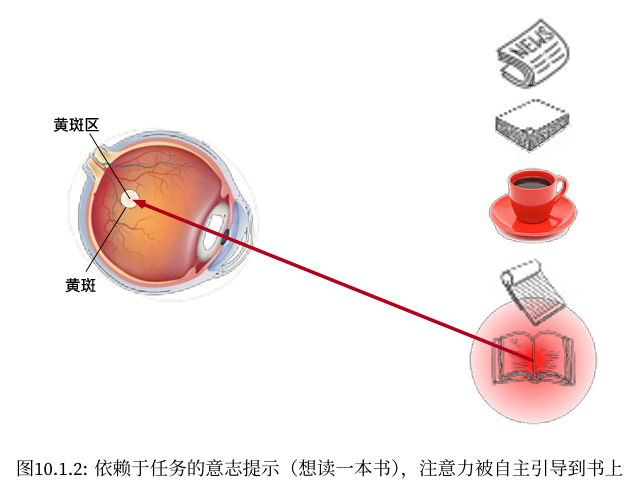
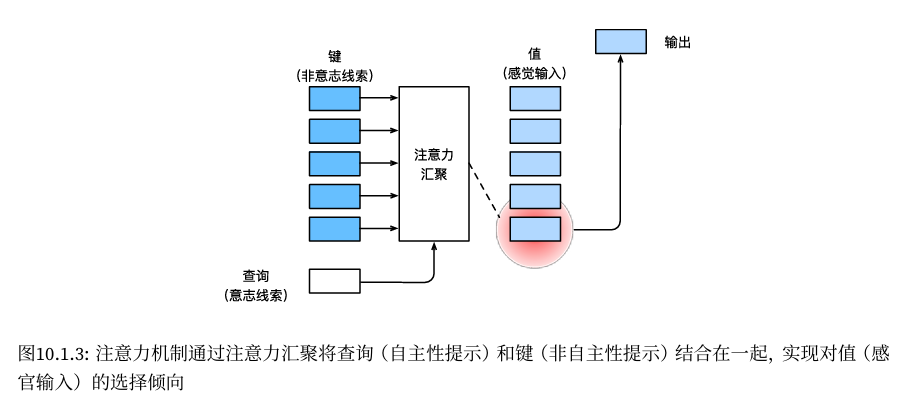
自主性提示被称为查询(query),即图10.2.2中“想要看书的想法”。感官输入被称为值(value),即图中的书本。每个值都与一个键(key)配对,这可以想象为感官输入的非自主提示,即“书”这个概念本身。
非自主提示基于突出性,自主提示则依赖于意识。
注意力汇聚
平均汇聚
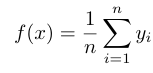
非参数注意力汇聚

带参数注意力汇聚

• Nadaraya‐Watson核回归的注意力汇聚是对训练数据中输出的加权平均。从注意力的角度来看,分配给 每个值的注意力权重取决于将值所对应的键和查询作为输入的函数。
• 注意力汇聚可以分为非参数型和带参数型。
注意力评分函数
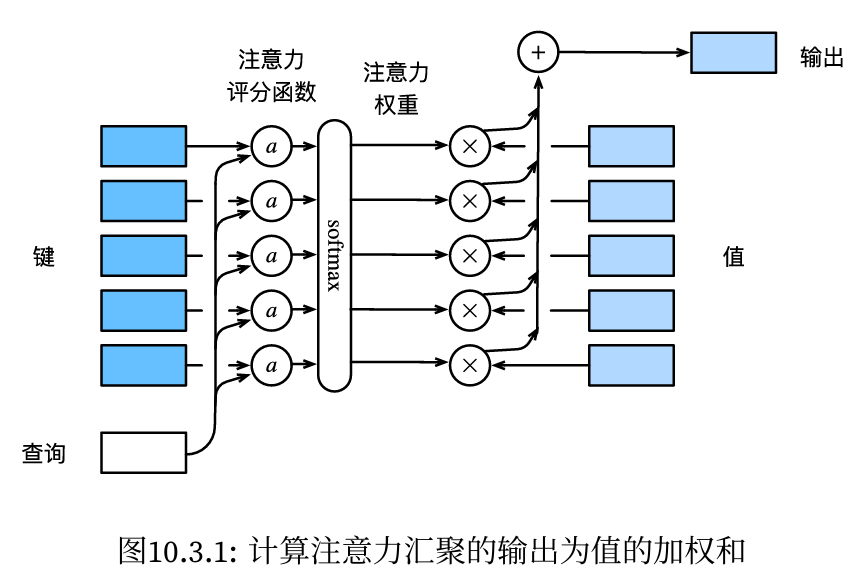

掩蔽softmax操作
加性注意力

缩放点积注意力

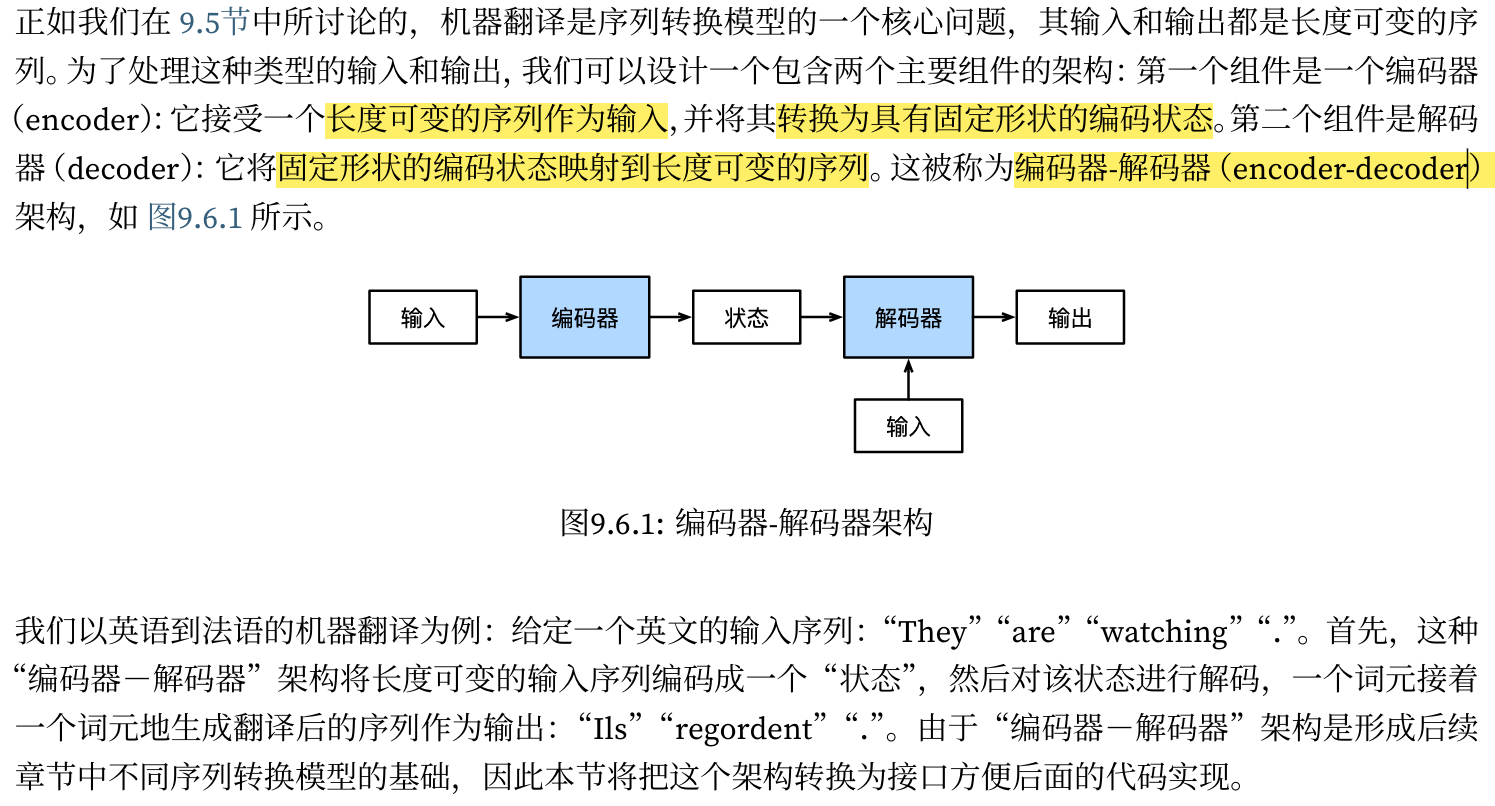
编码器-解码器架构
为了处理长度可变的输入和输出序列,我们使用编码器-解码器架构。
序列到序列学习(seq2seq)
整体模型
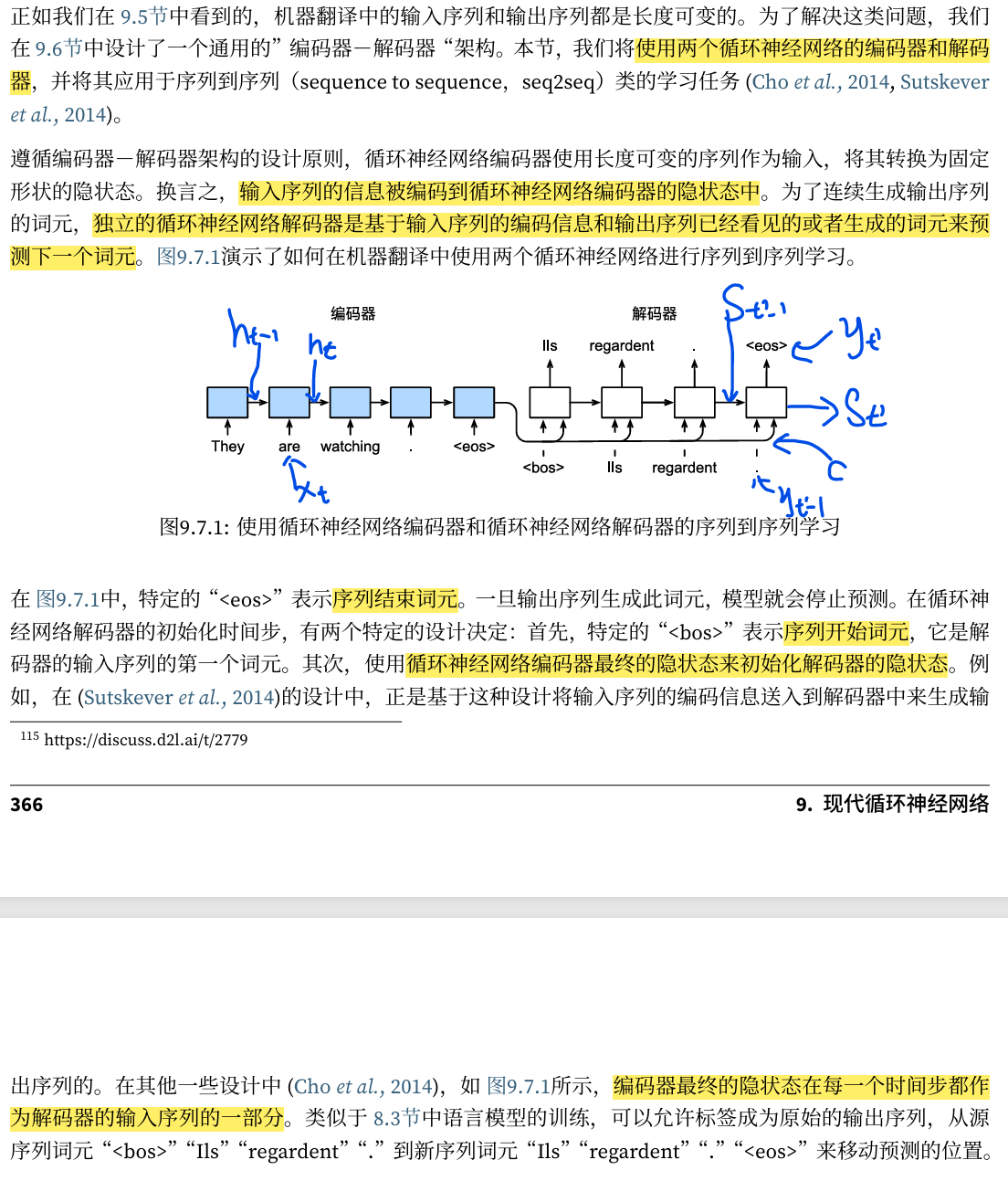
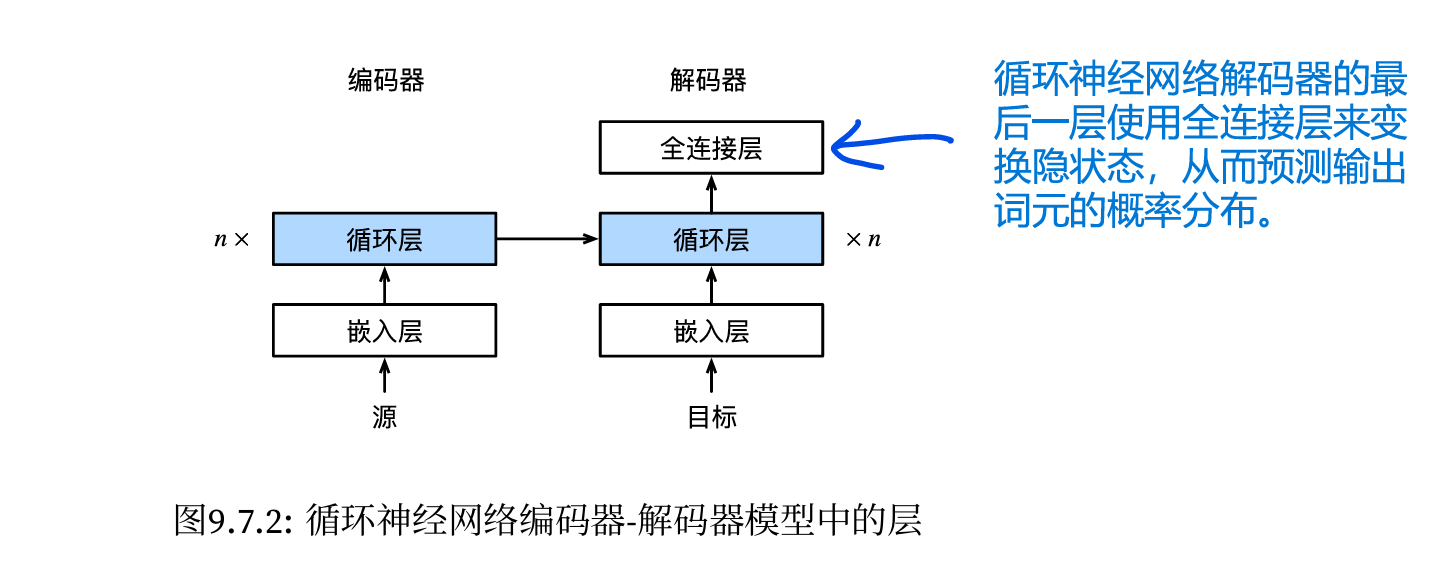
编码器

解码器

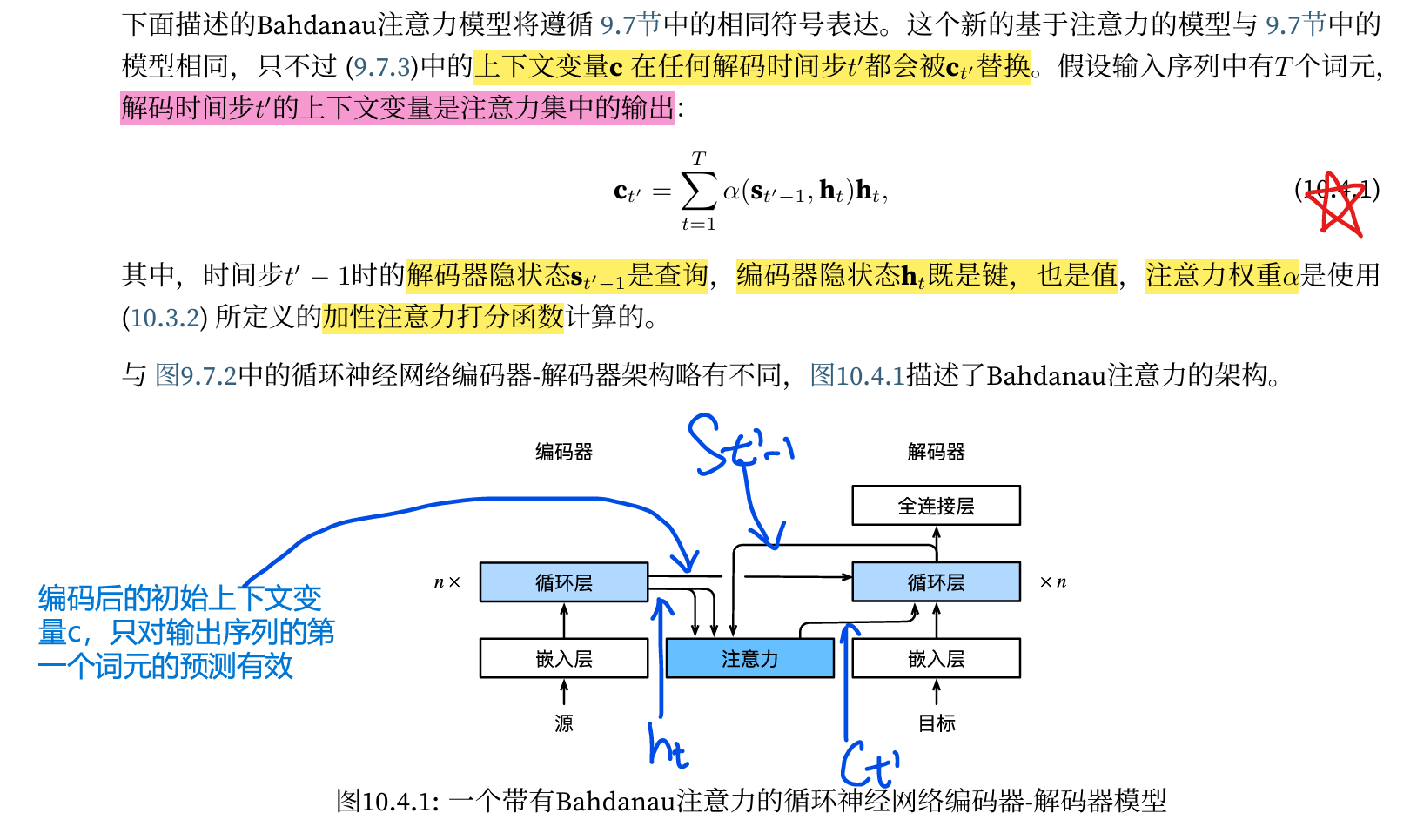
Bahdanau注意力
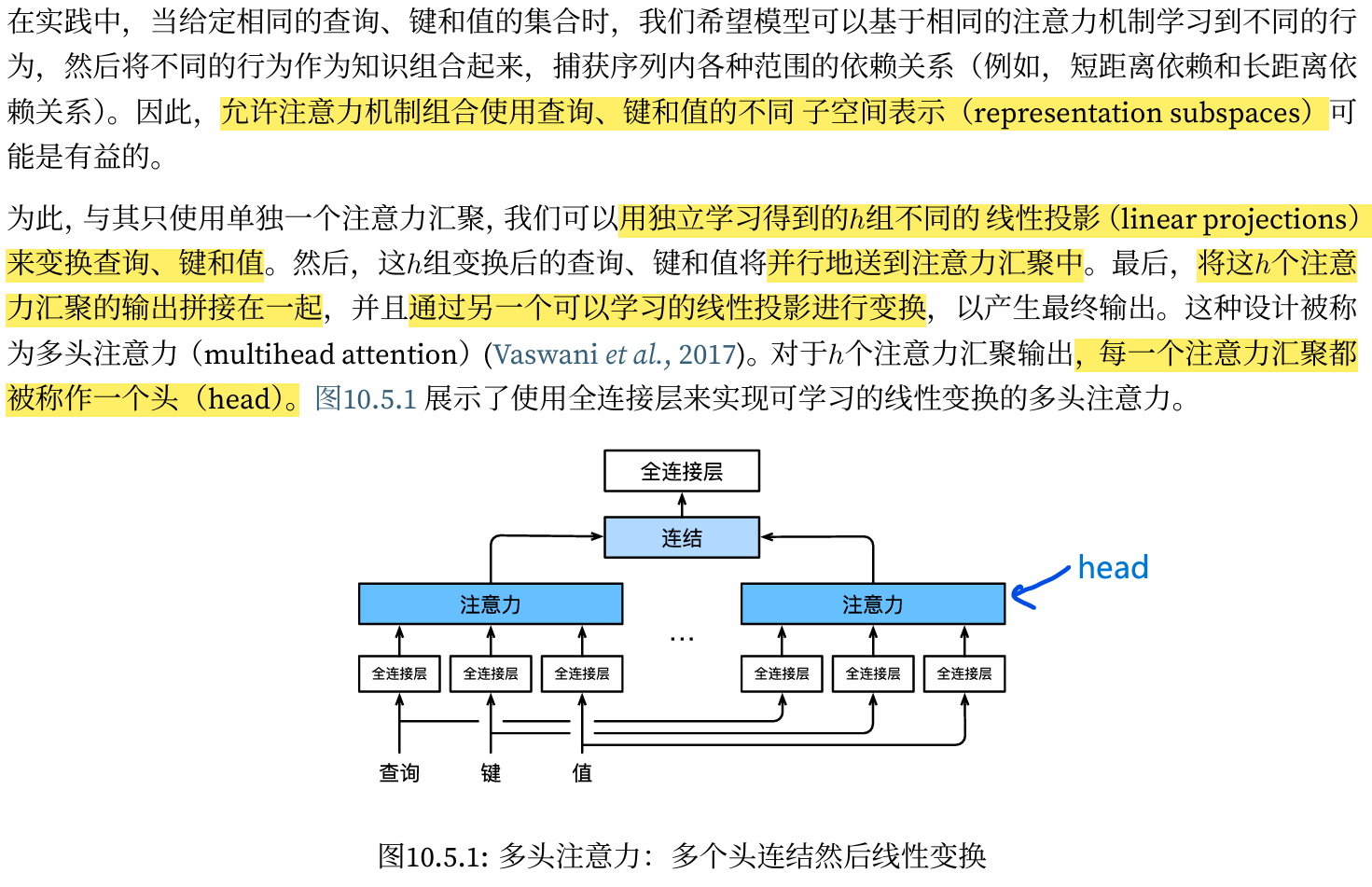
多头注意力

自注意力和位置编码
有了注 意力机制之后,我们将词元序列输入注意力池化中,以便同一组词元同时充当查询、键和值。具体来说,每个 查询都会关注所有的键-值对并生成一个注意力输出。

卷积神经网络和自注意力都拥有并行计算的优势,而且自注意力的最大路径长度最短。但是因为其计 算复杂度是关于序列长度的二次方,所以在很长的序列中计算会非常慢。
为了使用序列的顺序信息,可以通过在输入表示中添加位置编码,来注入绝对的或相对的位置信息。

逐位置前馈网络(Position-wise Feed-Forward Network, FFN)
核心概念与定位
1.逐位置独立处理:序列长度维度无交互,仅在特征维度做变换,同一组参数共享于所有位置,等价于序列维度的 1×1 卷积。
2.功能分工:注意力机制负责跨位置上下文聚合(“从哪儿拿信息”),FFN 负责位置内特征的非线性精炼(“拿到后怎么加工”),两者互补提升模型能力。
3.残差与归一化:标准实现包含残差连接与层归一化(LayerNorm),缓解梯度消失,加速训练收敛。
关键作用与价值
- 增加非线性表达:注意力输出为线性组合,FFN 引入非线性,使模型能学习语言中的隐喻、歧义等复杂模式。
- 提升模型容量:通过维度扩张与两层变换,增加可学习参数,增强特征拟合能力。
- 特征精炼与维度转换:在高维空间挖掘细粒度特征,再压缩回原维度,输出更具区分度的表示。
- 高效并行:逐位置独立计算,序列维度可完全并行,适合 GPU/TPU 加速,训练与推理效率高。
逐位置前馈网络是 Transformer 的核心组件,通过 “独立处理 + 非线性变换 + 残差连接”,与注意力层协同,在保持高效并行的同时,显著提升模型的特征表达能力。其简洁结构与强大功能,使其成为大语言模型(LLM)与序列建模任务中不可或缺的部分。
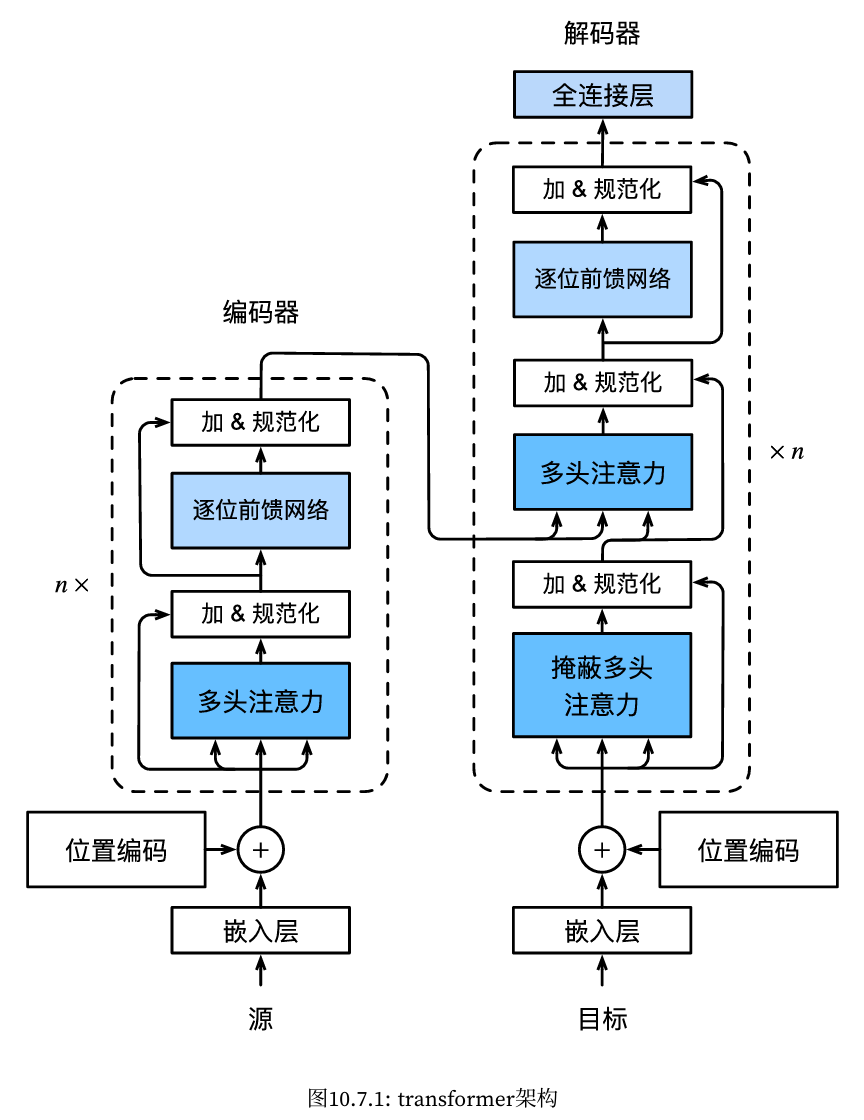
Transformer
Trans former的编码器和解码器是基于自注意力的模块叠加而成的,源(输入)序列和目标(输出)序列的嵌入 (embedding)表示将加上位置编码(positionalencoding),再分别输入到编码器和解码器中。

思考(为什么自注意力能解决长序列依赖?)
自注意力打破了传统序列模型的“顺序依赖计算范式”,用全局并行的注意力权重建模替代了 RNN/CNN 的 “局部逐步信息传递”,让序列中任意两个位置直接建立连接,无论距离多远,都能通过注意力权重直接交互信息,且全程并行计算、梯度直接传播。