

滑动窗口算法框架
123456789101112131415161718192021222324252627282930313233343536// 滑动窗口算法伪码框架void slidingWindow(string s) { // 用合适的数据结构记录窗口中的数据,根据具体场景变通 // 比如说,我想记录窗口中元素出现的次数,就用 map // 如果我想记录窗口中的元素和,就可以只用一个 int auto window = ... int left = 0, right = 0; while (right < s.size()) { // c 是将移入窗口的字符 char c = s[right]; window.add(c); // 增大窗口 right++; // 进行窗口内数据的一系列更新 ... // *** debug 输出的位置 *** printf("window: [%d,...
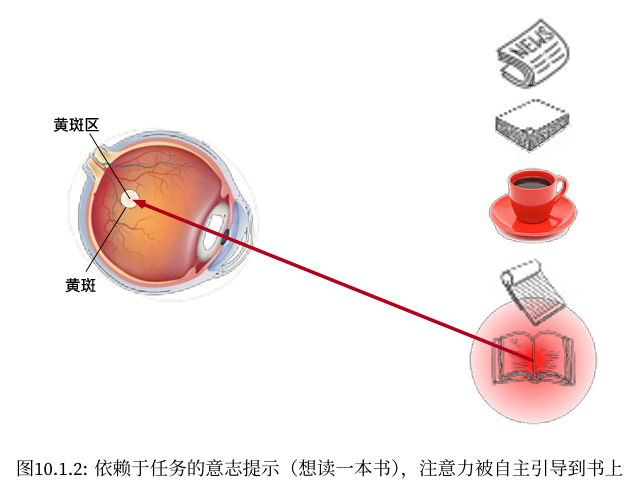
注意力机制
注意力提示 自主性提示被称为查询(query),即图10.2.2中“想要看书的想法”。感官输入被称为值(value),即图中的书本。每个值都与一个键(key)配对,这可以想象为感官输入的非自主提示,即“书”这个概念本身。 非自主提示基于突出性,自主提示则依赖于意识。 注意力汇聚平均汇聚 非参数注意力汇聚 带参数注意力汇聚 • Nadaraya‐Watson核回归的注意力汇聚是对训练数据中输出的加权平均。从注意力的角度来看,分配给 每个值的注意力权重取决于将值所对应的键和查询作为输入的函数。 • 注意力汇聚可以分为非参数型和带参数型。 注意力评分函数 掩蔽softmax操作 加性注意力 缩放点积注意力 编码器-解码器架构为了处理长度可变的输入和输出序列,我们使用编码器-解码器架构。 序列到序列学习(seq2seq)整体模型 编码器 解码器 Bahdanau注意力 多头注意力 自注意力和位置编码有了注 意力机制之后,我们将词元序列输入注意力池化中,以便同一组词元同时充当查询、键和值。具体来说,每个 查询都会关注所有的键-值对并生成一个注意力输出。 ...

卷积神经网络
1.2 边缘检测示例 示例中为灰度图像,所以图片维度为(6,6,1) 1.4 Padding 在边缘填充像素,padding为填充的像素层数 当$p=\frac{f-1}{2}$时输出的图像大小和原图像大小一样,f通常是奇数,推荐只用f为奇数的过滤器 1.5 卷积步长 目标矩阵为$n\times n$,内核大小为$f \times f$,padding为p,strides为2,则卷积得出的矩。阵大小为$(\llcorner\frac{n+2p-f}{s}+1\lrcorner) \times (\llcorner\frac{n+2p-f}{s}+1\lrcorner)$,其中对结果进行向下取整。 数学教科书中的卷积运算在进行之前要先将内核矩阵根据负对角线进行翻转然后才继续操作。 计算机的卷积运算在数学层面上叫做互相关,不需要进行翻转。 1.6...
机器学习策略
1.1 为什么是ML策略 ML策略有助于快速地判断哪些想法是靠谱的,或者甚至提出新的想法 1.2 正交化 Orthogonalization:每次只调整部分性质,而其他性质不改变,从而调整整体模型,即调整时各个性质之间不会相互影响 1.3 单一数字评估指标 查准率(P):识别到是cat的样本中实际上确实为cat的图片的百分比 查全率(R):对所有cat的图片,模型识别出的图片所占的百分比 单一数字评估指标 F1分数:P和R的调和平均数($\frac{2}{\frac{1}{P}+\frac{1}{R}}$) 1.4 满足和优化指标若有N个指标,则选择其中1个作为优化指标,其他N-1个作为满足指标,满足指标的运行结果只要到达某一个阈值即可。 1.5 训练_开发__测试集划分 开发集和训练集必须要处于同一分布中
决策树
决策树参考教程:(超爽中英!) 2025公认最好的【吴恩达机器学习】教程!附课件代码 Machine Learning Specialization C2 - Advanced Learning Algorithms-week4 学习过程 测量纯度 $H(p_1)$表示$p_1$的熵值,表示不纯度,熵值越大表示样本集越不纯(pure) 熵函数: $p_0=1-p_1$ $H(p_1)=-p_1log_2(p_1)-p_0log_2(p_0)=-p_1log_2(p_1)-(1-p_1)log_2(1-p_1)$ 取log的底数为2使得函数的峰值为1,把0log(0)看作0 选择拆分信息增益 熵:$H(p)=-\sum_{i=1}^{n}p_ilog_2p_i$ 条件熵:$H(Y|X)=\sum_{i=1}^np_iH(Y|X=x_i)$ 信息增益:$g(X,Y)=H(Y)-H(Y|X)$ 整合 使用独热编码 当决策树中的某个特征的离散值数量超过两个时可以使用 one hot...
提升神经网络的性能
Course 21.10 梯度消失与梯度爆炸 梯度函数呈指数级增长或指数级递减,导致训练难度上升 梯度下降算法的步长需要非常小,要花费很长时间来学习 1.11 神经网络的权重随机初始化 当使用ReLU函数时设置初始权重的方差为2/n,使用其他激活函数(如tanh)时可设置方差为1/n,降低梯度消失和爆炸问题 目的是为了训练出权重和梯度不会增长或消失过快的深度网络 1.12 梯度的数值逼近 双边公差为3.0001,单边公差为3.0301,双边误差比单边误差更小 1.13 梯度检验 检查误差的式子中的分母用于预防向量太小或太大 1.14 关于梯度检验实现的注记 使用dropout正则化后很难计算代价函数J,因此不能同时使用dropout正则化和梯度检验 在随机初始化过程中运行梯度检验,然后再训练网络,此时w和b不接近于0,可以更好地确定w和b;若随机初始化值比较小,则反复训练神经网络之后再重新运行梯度检验 2.1 Mini-batch 梯度下降法 mini-batch梯度下降法比batch梯度下降法运行地更快 2.2...

MySQL笔记(基本操作)
MySQL笔记(基本操作)参考教程: 黑马程序员MySQL知识精讲+mysql实战案例_零基础mysql数据库入门到高级全套教程 DDL列出现有数据库: 1show databases; 创建数据库: 12create database mydb1; # 数据库存在时会报错create database if not EXISTS mydb1 ; 选择使用数据库: 1use mydb1; 删除数据库: 12drop database mydb1; # 数据库不存在时会报错drop database if exists mydb1; 修改数据库编码: 1alter database mysql1 character set utf8; 创建表: 12345678create table if not exists student( sid int, `name` varchar(20), gender varchar(10), age int, birth date, address...

python语法笔记
python语法笔记参考教材: Python编程基础1.Python基础操作符(按优先级从左到右排列): * * / // % + - 字符串连接: 'Alice'+' hello' 输出:’Alice hello’ 字符串复制(格式只能是 字符串*整数值): 'Alice'*5 输出:’AliceAliceAliceAliceAlice’ 赋值语句:可以覆写变量,不用声明数据类型 变量名中不允许有 短横线、空格、数字开头、特殊字符 注释使用 # 输入输出函数: 1234print('hello,world')myName=input()print('It is good to meet you, '+myName)print(len(myName)) str()函数可以传入一个整数值并求值为它的字符串形式 12>>>...

第6章 变治法
6.1 预排序例1 检验数组中元素的唯一性 例2 找出数字列表中最常出现的数值 6.2 高斯消去法 前向消去 其中代码for k<-n+1 downto i do使得A[j,i]在最后更新 采用了部分选主元法的前向消去 6.5 霍纳法则和二进制幂霍纳法则 12345678910111213141516171819202122#include <iostream>#include <vector>// 使用霍纳法则计算多项式的值double horner(const std::vector<double>& coefficients, double x) { double result = coefficients.back(); for (int i = coefficients.size() - 2; i >= 0; --i) { result = result * x + coefficients[i]; } return...
第5章 分治法
5.1 合并排序 5.5 用分治法解最近对问题和凸包问题最近对问题